import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import pearsonr
from sklearn.feature_selection import mutual_info_regression
from funpymodeling import status, freq_tbl, profiling_num, freq_plot, cross_plot, plot_num
from matplotlib.colors import Normalize
from matplotlib.cm import ScalarMappable
import warnings
warnings.filterwarnings('ignore')
try:
from minepy import MINE
HAS_MINEPY = True
except Exception:
HAS_MINEPY = False
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (10, 6)
# --- Helpers MINE (usados en todo el capítulo) ---
def calc_mic(x, y, alpha=0.6):
if HAS_MINEPY:
m = MINE(alpha=alpha, c=15)
m.compute_score(x, y)
return m.mic()
# Fallback para entornos sin minepy: aproximamos con Mutual Information.
x_arr = np.asarray(x).reshape(-1, 1)
y_arr = np.asarray(y)
return float(mutual_info_regression(x_arr, y_arr, random_state=42)[0])
def calc_mas(x, y, alpha=0.6):
if HAS_MINEPY:
m = MINE(alpha=alpha, c=15)
m.compute_score(x, y)
return m.mas()
# MAS solo está disponible en minepy.
return np.nan
def calc_mic_r2(x, y, alpha=0.6):
return calc_mic(x, y, alpha) - pearsonr(x, y)[0]**2
# cross_plot, freq_plot y plot_num se importan de funpymodeling
# --- Cargar heart_disease ---
url = ("https://archive.ics.uci.edu/ml/"
"machine-learning-databases/"
"heart-disease/processed.cleveland.data")
column_names = ['age', 'sex', 'chest_pain', 'resting_blood_pressure',
'serum_cholesterol', 'fasting_blood_sugar', 'resting_ecg',
'max_heart_rate', 'exer_angina', 'oldpeak', 'slope',
'ca', 'thal', 'has_heart_disease']
heart_disease = pd.read_csv(url, names=column_names, na_values='?')
heart_disease['has_heart_disease'] = (heart_disease['has_heart_disease'] > 0).astype(int)1 Análisis exploratorio de datos
1.1 Análisis numérico

“La voz de los números” – una metáfora de Eduardo Galeano. Escritor y novelista.
Los datos que exploramos podrían ser como jeroglíficos egipcios sin una interpretación correcta. El análisis numérico es el primer paso de una serie de etapas iterativas en la búsqueda de lo que los datos nos quieren decir, si somos lo suficientemente pacientes para escucharlos.
Este capitulo abarcará, con unas pocas funciones, el análisis numérico completo de datos. Esto debería ser el primer paso en cualquier proyecto de datos, donde comenzamos sabiendo cuáles son los tipos correctos de datos y exploramos las distribuciones de variables numéricas y categóricas.
También se enfocará en la extracción de conclusiones semánticas, que será útil a la hora de escribir informes para audiencias no especializadas.
¿Qué vamos a repasar en este capítulo?
- Estado de salud de un conjunto de datos:
- Obtener métricas como el número total de filas, columnas, tipos de datos, ceros, y valores faltantes
- Cómo cada uno de los ítems mencionados impactan sobre diferentes análisis
- Cómo filtrar y operar rápidamente sobre (y con) ellos para limpiar los datos
- Análisis univariado en una variable categórica:
- Frecuencia, porcentaje, valor acumulativo, y gráficos coloridos
- Análisis univariado con variables numéricas:
- Percentil, dispersión, desvío estándar, promedio, valores máximos y mínimos
- Percentil vs. cuantil vs. cuartil
- Curtosis, asimetría, rango intercuartil, coeficiente de variación
- Gráficos de distribuciones
- Estudio de caso completo basado en “Data World”, preparación de datos, y análisis de datos
Repaso de funciones utilizadas en el capítulo:
status(data): Análisis de la estructura del conjunto de datos (defunpymodeling)freq_tbl(data): Análisis categórico (cuantitativo y gráfico) (defunpymodeling)profiling_num(data): Análisis para variables numéricas (cuantitativas) (defunpymodeling)plot_num(data): Análisis para variables numéricas (gráficos) (defunpymodeling)
Nota: Todas las funciones mencionadas se encuentran en el paquete funpymodeling, el equivalente en Python de funModeling de R. La función describe se encuentra en pandas.
1.1.1 Estado de salud de un conjunto de datos
La cantidad de ceros, NA, Inf, valores únicos al igual que el tipo de datos puede llevar a un buen o mal modelo. Aquí, un acercamiento al primer paso del modelado de datos.
Primero, vamos a cargar las bibliotecas necesarias y los datos.
1.1.1.1 Buscar valores faltantes, ceros, tipos de datos y valores únicos
Probablemente uno de los primeros pasos, cuando recibimos un nuevo conjunto de datos para analizar, es verificar si existen valores faltantes (NaN en Python) y el tipo de datos.
La función status incluida en funpymodeling nos puede ayudar mostrándonos estas cifras en valores relativos y porcentuales. También obtiene las estadísticas de infinitos y ceros.
# Analizar los datos ingresados
st = status(heart_disease).round(2)
print(st[['variable', 'q_zeros', 'p_zeros',
'q_nan', 'p_nan']].to_string(index=False))
print(st[['variable', 'q_inf', 'p_inf',
'type', 'unique']].to_string(index=False)) variable q_zeros p_zeros q_nan p_nan
age 0 0.00 0 0.00
sex 97 0.32 0 0.00
chest_pain 0 0.00 0 0.00
resting_blood_pressure 0 0.00 0 0.00
serum_cholesterol 0 0.00 0 0.00
fasting_blood_sugar 258 0.85 0 0.00
resting_ecg 151 0.50 0 0.00
max_heart_rate 0 0.00 0 0.00
exer_angina 204 0.67 0 0.00
oldpeak 99 0.33 0 0.00
slope 0 0.00 0 0.00
ca 176 0.58 4 0.01
thal 0 0.00 2 0.01
has_heart_disease 164 0.54 0 0.00
variable q_inf p_inf type unique
age 0 0.0 float64 41
sex 0 0.0 float64 2
chest_pain 0 0.0 float64 4
resting_blood_pressure 0 0.0 float64 50
serum_cholesterol 0 0.0 float64 152
fasting_blood_sugar 0 0.0 float64 2
resting_ecg 0 0.0 float64 3
max_heart_rate 0 0.0 float64 91
exer_angina 0 0.0 float64 2
oldpeak 0 0.0 float64 40
slope 0 0.0 float64 3
ca 0 0.0 float64 4
thal 0 0.0 float64 3
has_heart_disease 0 0.0 int64 2Diccionario de datos:
age: Edadsex: Sexochest_pain: Tipo de dolor en el pechoresting_blood_pressure: Presión arterial en repososerum_cholesterol: Colesterol séricofasting_blood_sugar: Azúcar en ayunas > 120 mg/dlresting_ecg: Resultados del ECG en reposomax_heart_rate: Frecuencia cardíaca máxima alcanzadaexer_angina: Angina inducida por ejerciciooldpeak: Depresión del ST inducida por ejercicio en relación al repososlope: Pendiente del segmento ST en ejercicio máximoca: Número de vasos principales coloreados por fluoroscopiathal: Thalassemia (tipos de thalassemia)has_heart_disease: Diagnóstico de enfermedad cardíaca (0 = no, 1 = sí)
Métricas de la función status:
q_zeros: cantidad de ceros (p_zeros: en porcentaje)q_inf: cantidad de valores infinitos (p_inf: en porcentaje)q_nan: cantidad de NA (p_nan: en porcentaje)type: tipo de datounique: cantidad de valores únicos
1.1.1.2 ¿Por qué son importantes estas métricas?
- Ceros: Las variables con muchos ceros pueden no ser útiles para modelar y, en algunos casos, pueden sesgar dramáticamente el modelo.
- NA: Varios modelos excluyen automáticamente las filas que tienen valores NA (random forest por ejemplo). En consecuencia, el modelo final puede resultar sesgado debido a varias filas faltantes por una sola variable. Por ejemplo, si los datos contienen tan sólo una de las 100 variables con el 90% de datos NA, el modelo se ejecutará con sólo el 10% de las filas originales.
- Inf: Los valores infinitos (
np.infen Python) pueden ocasionar un comportamiento inesperado en algunas funciones. - Type: Algunas variables están codificadas como números, pero son códigos o categorías y los modelos no las manejan de la misma manera.
- Unique: Las variables categóricas con un alto número de valores diferentes (~30) tienden a sobreajustar si las categorías tienen una baja cardinalidad (árboles de decisión, por ejemplo).
1.1.1.3 Filtrar casos no deseados
La función status toma un DataFrame y genera una tabla de estado que nos puede ayudar a quitar rápidamente atributos (o variables) en base a todas las métricas descriptas en la sección anterior. Por ejemplo:
Quitar variables con un alto número de ceros
# Analizar los datos ingresados
my_data_status = status(heart_disease)
# Quitar las variables que tienen un 60% de valores cero
vars_to_remove = my_data_status[my_data_status['p_zeros'] > 0.6]['variable'].tolist()
print(f"Variables a remover: {vars_to_remove}")
# Conservar todas las columnas excepto aquellas presentes en la lista 'vars_to_remove'
heart_disease_2 = heart_disease.drop(columns=vars_to_remove)Variables a remover: ['fasting_blood_sugar', 'exer_angina']Ordenar datos según el porcentaje de ceros
sorted_status = my_data_status.sort_values('p_zeros', ascending=False)[['variable', 'q_zeros', 'p_zeros']].round(2)
print(sorted_status) variable q_zeros p_zeros
5 fasting_blood_sugar 258 0.85
8 exer_angina 204 0.67
11 ca 176 0.58
13 has_heart_disease 164 0.54
6 resting_ecg 151 0.50
9 oldpeak 99 0.33
1 sex 97 0.32
0 age 0 0.00
2 chest_pain 0 0.00
3 resting_blood_pressure 0 0.00
4 serum_cholesterol 0 0.00
7 max_heart_rate 0 0.00
10 slope 0 0.00
12 thal 0 0.00El mismo razonamiento aplica cuando queremos quitar (o conservar) aquellas variables que estén por encima o por debajo de determinado umbral. Por favor revisen el capítulo de valores faltantes para obtener más informaación sobre las implicancias de trabajar con variables que contienen valores faltantes.
1.1.1.4 Profundizar en estos temas
Los valores que devuelve la función status son abordados en profundidad en otros capítulos:
- Valores faltantes el tratamiento, análisis e imputación de (NA) son abordados en el capítulo Datos faltantes.
- Tipos de datos, las conversiones e implicancias de trabajar con distintos tipos de datos y más temas son abordados en el capítulo Tipos de datos.
- Un alto número de valores únicos es sinónimo de variables de alta cardinalidad. Estudiamos esta situación en los siguientes capítulos:
1.1.1.5 Obtener otras estadísticas comunes: cantidad total de filas, cantidad total de columnas y nombres de columnas:
print(f"Cantidad de filas: {heart_disease.shape[0]}")
print(f"Cantidad de columnas: {heart_disease.shape[1]}")
import textwrap
cols_str = str(heart_disease.columns.tolist())
print("Nombres de columnas:")
print(textwrap.fill(cols_str, width=60))Cantidad de filas: 303
Cantidad de columnas: 14
Nombres de columnas:
['age', 'sex', 'chest_pain', 'resting_blood_pressure',
'serum_cholesterol', 'fasting_blood_sugar', 'resting_ecg',
'max_heart_rate', 'exer_angina', 'oldpeak', 'slope', 'ca',
'thal', 'has_heart_disease']1.1.2 Análisis de variables categóricas
Asegúrense de tener la última version de ‘funpymodeling’.
La función freq_tbl simplifica el análisis de frecuencia o distribución. Dicha función vuelca la distribución en una tabla y muestra la distribución de números absolutos y relativos.
Si desean obtener la distribución de variables categóricas:
# Analizar variables categóricas específicas
# Convertimos a 'category' en una copia para que freq_tbl las reconozca
heart_disease_cat = heart_disease[['thal', 'chest_pain']].astype('category')
# Analizar frecuencias con tabla
print(freq_tbl(heart_disease_cat))
# Visualizar con gráfico (incluye NaN)
freq_plot(heart_disease, input=['thal', 'chest_pain']) thal frequency percentage cumulative_perc
0 3.0 166 0.5479 0.5479
1 7.0 117 0.3861 0.9340
2 6.0 18 0.0594 0.9934
3 NA 2 0.0066 1.0000
----------------------------------------------------------------
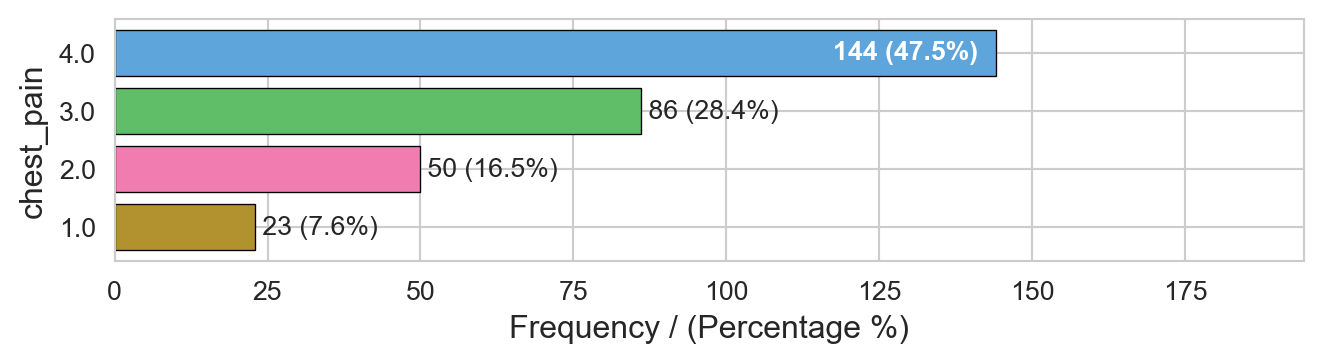
chest_pain frequency percentage cumulative_perc
0 4.0 144 0.4752 0.4752
1 3.0 86 0.2838 0.7590
2 2.0 50 0.1650 0.9240
3 1.0 23 0.0759 1.0000
----------------------------------------------------------------
Variables processed: thal, chest_pain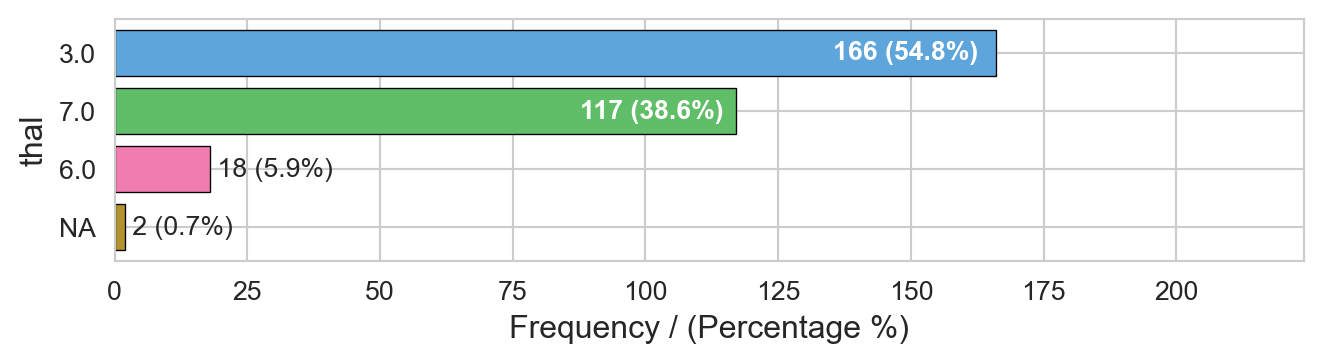
Al igual que en las demás funciones de funpymodeling, si se pasa todo el DataFrame, entonces la función se ejecutará para todas las variables categóricas que estén presentes:
freq_tbl(heart_disease)Si sólo queremos obtener la tabla sin el gráfico, entonces usamos freq_tbl directamente. El ejemplo freq_tbl también puede trabajar con una variable singular. Por defecto, los valores NA son considerados tanto en la tabla como en el gráfico. Si es necesario excluir los valores NA, entonces usen el parámetro na_rm=True en freq_plot.
# Análisis de una sola variable
freq_tbl(heart_disease['thal'])Si sólo se brinda una variable, entonces freq_tbl generará la tabla; por lo tanto, es fácil realizar algunos cálculos en base a las variables que brinda.
- Por ejemplo, para visualizar las categorías que representan la mayor parte del 80% (en base a
cumulative_perc < 80). - Para obtener las categorías que pertenecen a la cola larga, es decir, filtrando por
percentage < 1e identificando aquellas categorías que aparecen menos del 1% de las veces.
1.1.2.0.1 Análisis
Los resultados están ordenados según la variable frequency, que rápidamente analiza las categorías con mayor frecuencia y qué porcentaje representan (variable cumulative_perc). En términos generales, a los seres humanos nos gusta el orden. Si las variables no están ordenadas, nuestros ojos empiezan a moverse por todas las barras para compararlas y nuestros cerebros ubican cada barra en relación a las demás.
En general, suele haber unas pocas categorías que aparecen la mayor parte del tiempo.
Pueden encontrar un análisis más completo en Variables de alta cardinalidad en estadística descriptiva.
1.1.2.1 Introduciendo la función describe
Esta función está incluida en pandas y nos permite analizar rápidamente un conjunto de datos completo para variables númericas.
heart_disease_3 = heart_disease[['thal', 'chest_pain']].copy()
# describe() de pandas muestra count, unique, top, freq para numéricas
print(heart_disease_3.describe(include='all'))
# Detalle adicional: n, missing y distribución
for col in heart_disease_3.columns:
s = heart_disease_3[col]
print(f"\n=== {col} === n: {s.notna().sum()}, missing: {s.isna().sum()}, unique: {s.nunique()}")
print(s.value_counts(dropna=False)) thal chest_pain
count 301.000000 303.000000
mean 4.734219 3.158416
std 1.939706 0.960126
min 3.000000 1.000000
25% 3.000000 3.000000
50% 3.000000 3.000000
75% 7.000000 4.000000
max 7.000000 4.000000
=== thal === n: 301, missing: 2, unique: 3
thal
3.0 166
7.0 117
6.0 18
NaN 2
Name: count, dtype: int64
=== chest_pain === n: 303, missing: 0, unique: 4
chest_pain
4.0 144
3.0 86
2.0 50
1.0 23
Name: count, dtype: int64Donde:
n: cantidad de filas que no sonNA. En este caso, indica que hay pacientes que contienen un número.missing: cantidad de valores faltantes. Al sumar este indicador yn, obtenemos la cantidad total de filas.unique: cantidad de valores únicos (o distintos).
El resto de la información es bastante similar a la función freq e indica entre paréntesis el número total en valores relativos y absolutos para cada categoría diferente.
1.1.3 Análisis de variables numéricas
Esta sección se divide en dos partes:
- Parte 1: Introducción al caso de estudio “World Data”
- Parte 2: Hacer el análisis numérico en Python
Si no desean saber cómo se calcula la etapa de preparación de datos de Data World, pueden saltar a “Parte 2: Haciendo el análisis numérico en Python”, cuando el análisis comenzó.
1.1.3.1 Parte 1: Introducción al caso de estudio “World Data”
Este estudio contiene muchos indicadores sobre el desarrollo mundial. Independientemente del ejemplo de análisis numérico, la idea es proveer una tabla lista para usar para sociólogos, investigadores, etc. interesados en analizar este tipo de datos.
La fuente original de los datos es: http://databank.worldbank.org. Allí encontrarán un diccionario de datos que explica todas las variables.
Primero, tenemos que hacer una limpieza de datos. Vamos a conservar el valor más reciente de cada indicador.
_url_wdi = (
"https://raw.githubusercontent.com/pablo14/"
"data-science-live-book/master/"
"exploratory_data_analysis/"
"World_Development_Indicators.csv")
data_world = pd.read_csv(_url_wdi, na_values="..")
data_world = data_world[
data_world['Series Code'].notna() &
(data_world['Series Code'] != "")]
# Obtener el valor más reciente (no NA) de cada fila
year_cols = [c for c in data_world.columns if 'YR' in c]
data_world['newest_value'] = data_world[year_cols].apply(
lambda row: row.dropna().iloc[-1]
if row.dropna().any() else np.nan, axis=1)
_cols_show = ['Series Name', 'Series Code',
'Country Name', 'Country Code']
with pd.option_context('display.max_colwidth', 28,
'display.width', 72):
print(data_world[_cols_show].head(3)) Series Name Series Code Country Name \
0 Population living in slu... EN.POP.SLUM.UR.ZS Afghanistan
1 Population living in slu... EN.POP.SLUM.UR.ZS Albania
2 Population living in slu... EN.POP.SLUM.UR.ZS Algeria
Country Code
0 AFG
1 ALB
2 DZA Las columnas Series.Name y Series.Code son los indicadores a analizar. Country.Name y Country.Code son los países. Cada fila representa una combinación única de país e indicador. Las columnas restantes, X1990..YR1990. (año 1990),X2000..YR2000. (año 2000), X2007..YR2007. (año 2007), y sucesivamente indican el valor de cada métrica para ese año, cada columna corresponde a un año.
1.1.3.2 Tomar decisiones como científicos de datos
Hay muchas celdas NAs porque algunos países no cuentan con las mediciones de los indicadores en esos años. En este punto, debemos tomar una decisión como científicos de datos. Probablemente no tomemos la decisión óptima si no consultamos con un experto, por ejemplo, un sociólogo.
¿Qué hacemos con los valores NA? En este caso, vamos a conservar el valor más reciente para todos los indicadores. Quizás esta no sea la mejor manera de extraer conclusiones para un paper académico, ya que vamos a comparar algunos países que cuentan con información actualizada al 2016 con países cuyos datos fueron actualizados por última vez en el 2009. Comparar todos los indicadores con los datos más recientes es un enfoque apropiado para un primer análisis.
Otra solución podría haber sido conservar el valor más reciente solamente si este es de los últimos cinco años. Esto reduciría la cantidad de países a analizar.
Estas preguntas son imposibles de responder para un sistema de inteligencia artificial, no obstante la decisión puede influir drásticamente en los resultados.
La última transformación
El próximo paso convertirá la última tabla de formato largo a ancho. En otras palabras, cada fila representará un país y cada columna un indicador (gracias a la última transformación que tiene el valor más reciente para cada combinación de indicador-país).
Los nombres de los indicadores son poco claros, por lo que “traduciremos” algunos de ellos.
# Obtener la lista de descripciones de indicadores.
names = data_world[['Series Name', 'Series Code']].drop_duplicates()
with pd.option_context('display.max_colwidth', 28,
'display.width', 72):
print(names.head(5))
# Convertir algunos nombres
df_conv_world = pd.DataFrame({
'new_name': ['urban_poverty_headcount',
'rural_poverty_headcount',
'gini_index',
'pop_living_slums',
'poverty_headcount_1.9'],
'Series Code': ['SI.POV.URHC',
'SI.POV.RUHC',
'SI.POV.GINI',
'EN.POP.SLUM.UR.ZS',
'SI.POV.DDAY']
})
# Agregar el nuevo valor del indicador
data_world_2 = data_world.merge(df_conv_world, on='Series Code', how='left')
data_world_2['Series_Code_2'] = data_world_2['new_name'].fillna(data_world_2['Series Code']) Series Name Series Code
0 Population living in slu... EN.POP.SLUM.UR.ZS
217 Income share held by sec... SI.DST.02ND.20
434 Income share held by thi... SI.DST.03RD.20
651 Income share held by fou... SI.DST.04TH.20
868 Income share held by hig... SI.DST.05TH.20El significado de cualquiera de los indicadores puede cotejarse en data.worldbank.org. Por ejemplo, si queremos saber qué significa EN.POP.SLUM.UR.ZS, ingresamos a: http://data.worldbank.org/indicator/EN.POP.SLUM.UR.ZS
# Convertir de formato largo a ancho usando pivot
data_world_wide = data_world_2.pivot_table(
index='Country Name',
columns='Series_Code_2',
values='newest_value',
aggfunc='first'
).reset_index()
# Visualizar las primeras tres filas
with pd.option_context('display.max_colwidth', 16,
'display.width', 72):
print(data_world_wide.iloc[:3, :5])Series_Code_2 Country Name SI.DST.02ND.20 SI.DST.03RD.20 \
0 Afghanistan NaN NaN
1 Albania 13.17 17.34
2 Algeria NaN NaN
Series_Code_2 SI.DST.04TH.20 SI.DST.05TH.20
0 NaN NaN
1 22.81 37.82
2 NaN NaN Nota: En Python, la conversión entre formatos largo y ancho se realiza con pivot_table y melt de pandas.
Ahora tenemos la tabla final para analizar.
1.1.3.3 Parte 2: Hacer el análisis numérico en Python
Utilizaremos las siguientes funciones:
describedepandasprofiling_num(análisis univariado completo), yplot_num(histogramas) defunpymodeling
Seleccionaremos solamente dos variables como ejemplo:
data_subset = data_world_wide[['gini_index', 'poverty_headcount_1.9']]
# describe con percentiles personalizados (equivalente a Hmisc::describe en R)
print(data_subset.describe(percentiles=[.05, .10, .25, .50, .75, .90, .95]))
# n, missing, unique
print(pd.DataFrame({'n': data_subset.notna().sum(), 'missing': data_subset.isna().sum(),
'unique': data_subset.nunique()}))
# Valores extremos
for col in data_subset.columns:
low = data_subset[col].nsmallest(5).tolist()
high = data_subset[col].nlargest(5).tolist()
print(f"\n{col}:")
print(f" lowest={low}")
print(f" highest={high}")Series_Code_2 gini_index poverty_headcount_1.9
count 140.000000 116.000000
mean 38.798571 18.333707
std 8.491816 22.744867
min 24.090000 0.000000
5% 26.814500 0.025000
10% 27.576000 0.075000
25% 32.347500 1.052500
50% 37.685000 6.000000
75% 43.922500 33.815000
90% 50.469000 54.045000
95% 53.534000 67.327500
max 63.380000 77.840000
n missing unique
Series_Code_2
gini_index 140 28 136
poverty_headcount_1.9 116 52 107
gini_index:
lowest=[24.09, 25.59, 25.9, 26.12, 26.13]
highest=[63.38, 60.97, 60.79, 60.46, 56.24]
poverty_headcount_1.9:
lowest=[0.0, 0.0, 0.0, 0.0, 0.01]
highest=[77.84, 77.08, 70.91, 68.74, 68.64]Tomando poverty_headcount_1.9 (Índice de pobreza de US$1.90 por día es el porcentaje de la población que vive con menos de US$1.90 por día a precios internacionales de 2011.), lo podemos describir como:
n: cantidad de filas que no sonNA. En este caso, indica que hay países que contienen un número.missing: cantidad de valores faltantes. Al sumar este indicador yn, obtenemos la cantidad total de filas. Casi la mitad de los países no tienen datos.unique: cantidad de valores únicos (o distintos).mean: el clásico promedio o media.- Números:
.05,.10,.25,.50,.75,.90y.95son percentiles. Estos valores son muy útiles ya que nos ayudan a describir la distribución. lowestyhighest: los cinco valores mínimos/máximos. Aquí podemos detectar valores atípicos y errores de datos.
La siguiente función es profiling_num, que toma un DataFrame y devuelve una gran tabla en la que es fácil sentirse abrumado por un mar de métricas.

Imagen de la película “Matrix” (1999), dirigida por las hermanas Wachowski.
La idea de la siguiente tabla es brindarle al usuario un conjunto completo de métricas para que él o ella pueda decidir cuáles utilizar para el estudio.
Nota: Detrás de cada métrica hay mucha teoría estadística. Aquí cubriremos solamente un enfoque acotado y muy simplificado para introducir los conceptos.
# El análisis numérico completo de una función automáticamente excluye las variables no numéricas
df_prof = profiling_num(data_world_wide)
print(df_prof[['variable', 'mean', 'std_dev', 'variation_coef']]) variable mean std_dev variation_coef
0 SI.DST.02ND.20 10.9403 2.1660 0.1980
1 SI.DST.03RD.20 15.1876 2.0341 0.1339
2 SI.DST.04TH.20 21.4564 1.4916 0.0695
3 SI.DST.05TH.20 45.8917 7.1386 0.1556
4 SI.DST.10TH.10 30.5108 6.7513 0.2213
5 SI.DST.FRST.10 2.5446 0.8695 0.3417
6 SI.DST.FRST.20 6.5247 1.8737 0.2872
7 SI.POV.2DAY 32.3706 30.6360 0.9464
8 SI.POV.GAP2 14.1630 16.4036 1.1582
9 SI.POV.GAPS 6.8922 10.0966 1.4649
10 SI.POV.NAGP 12.2467 10.1167 0.8261
11 SI.POV.NAHC 30.6953 17.8845 0.5826
12 SI.POV.RUGP 15.8700 11.8254 0.7451
13 SI.POV.URGP 8.2820 8.2393 0.9948
14 SI.SPR.PC40 10.3064 9.7540 0.9464
15 SI.SPR.PC40.ZG 1.9585 3.6212 1.8490
16 SI.SPR.PCAP 21.0660 17.4407 0.8279
17 SI.SPR.PCAP.ZG 1.4575 3.2075 2.2007
18 gini_index 38.7986 8.4918 0.2189
19 pop_living_slums 45.6990 23.6568 0.5177
20 poverty_headcount_1.9 18.3337 22.7449 1.2406
21 rural_poverty_headcount 41.2394 21.9073 0.5312
22 urban_poverty_headcount 23.2812 15.0599 0.6469print(df_prof[['variable', 'p_01', 'p_05',
'p_25', 'p_50']])
print()
print(df_prof[['variable', 'p_75', 'p_95', 'p_99']]) variable p_01 p_05 p_25 p_50
0 SI.DST.02ND.20 5.5680 7.3605 9.5275 11.1350
1 SI.DST.03RD.20 9.1374 11.8275 13.8775 15.4600
2 SI.DST.04TH.20 16.2861 18.2885 20.7575 21.9100
3 SI.DST.05TH.20 35.0043 36.3595 40.4950 44.8250
4 SI.DST.10TH.10 20.7292 21.9885 25.7100 29.4950
5 SI.DST.FRST.10 0.9156 1.1475 1.8850 2.5400
6 SI.DST.FRST.20 2.6143 3.3695 5.0925 6.5050
7 SI.POV.2DAY 0.0605 0.3925 3.8275 20.2700
8 SI.POV.GAP2 0.0115 0.0850 1.3050 5.5250
9 SI.POV.GAPS 0.0000 0.0000 0.2875 1.4150
10 SI.POV.NAGP 0.4207 1.2250 4.5000 8.6500
11 SI.POV.NAHC 1.8420 6.4300 16.3500 26.6000
12 SI.POV.RUGP 0.7400 1.6500 5.9500 13.6000
13 SI.POV.URGP 0.3000 0.9000 2.9000 6.3000
14 SI.SPR.PC40 0.8565 1.2285 3.4750 6.9450
15 SI.SPR.PC40.ZG -6.2318 -3.0211 -0.0845 1.7137
16 SI.SPR.PCAP 2.4264 3.1375 8.0025 15.2750
17 SI.SPR.PCAP.ZG -5.8972 -3.8050 -0.4864 1.3242
18 gini_index 25.7109 26.8145 32.3475 37.6850
19 pop_living_slums 6.8300 10.7500 25.1750 46.2000
20 poverty_headcount_1.9 0.0000 0.0250 1.0525 6.0000
21 rural_poverty_headcount 2.9020 6.4650 25.2500 38.1000
22 urban_poverty_headcount 0.5790 3.1400 12.7075 20.1000
variable p_75 p_95 p_99
0 SI.DST.02ND.20 12.6125 14.2005 14.5722
1 SI.DST.03RD.20 16.6975 17.8620 18.1444
2 SI.DST.04TH.20 22.5225 23.0130 23.3876
3 SI.DST.05TH.20 49.8275 58.1150 65.8940
4 SI.DST.10TH.10 34.1150 42.2115 50.6165
5 SI.DST.FRST.10 3.2375 3.8820 4.3466
6 SI.DST.FRST.20 8.0000 9.3920 9.9966
7 SI.POV.2DAY 63.2050 84.5775 90.3410
8 SI.POV.GAP2 26.3000 48.5300 56.1785
9 SI.POV.GAPS 10.2925 31.4550 38.2880
10 SI.POV.NAGP 16.9500 32.4250 36.7200
11 SI.POV.NAHC 44.2500 62.9800 71.6400
12 SI.POV.RUGP 22.4500 37.7000 45.2900
13 SI.POV.URGP 9.9500 25.1500 35.1700
14 SI.SPR.PC40 12.6925 28.8675 35.3502
15 SI.SPR.PC40.ZG 4.6430 7.9291 8.9969
16 SI.SPR.PCAP 25.4150 52.8370 67.1686
17 SI.SPR.PCAP.ZG 3.5580 7.0165 8.4814
18 gini_index 43.9225 53.5340 60.8998
19 pop_living_slums 65.6250 83.3750 93.4150
20 poverty_headcount_1.9 33.8150 67.3275 76.1545
21 rural_poverty_headcount 57.6000 75.7760 81.6960
22 urban_poverty_headcount 31.1750 51.0350 61.7540Cada indicador tiene su raison d’être:
variable: nombre de la variablemean: el famoso promedio o mediastd_dev: desvío estándar, una medida de dispersión o extensión con respecto al valor promedio. Un valor cerca de0indica que casi no hay variación (por lo que parece más una constante); por otro lado, es más difícil definir qué sería un valor alto, pero podemos decir que a mayor variación, mayor dispersión. El caos se asemeja a un desvío estándar de valor infinito. La unidad es la misma que la del promedio para que puedan compararse.variation_coef: coeficiente de variación=std_dev/mean. Dado que elstd_deves un valor absoluto, es bueno tener un indicador que lo exprese en un valor relativo, comparando elstd_devcontra elmeanUn valor de0.22indica que elstd_deves el 22% delmean. Si estuviera cerca de0entonces la variable estaría más centrada cerca del promedio. Si comparamos dos clasificadores, entonces es probable que prefiramos el que tenga menoresstd_devyvariation_coefpor su precisión.p_01,p_05,p_25,p_50,p_75,p_95,p_99: Percentiles en 1%, 5%, 25%, y así sucesivamente. Encontrarán un repaso completo sobre percentiles más adelante en este capítulo.
Para leer una explicación completa sobre percentiles, por favor diríjanse a: APÉNDICE.
skewness: es una medida de asimetría. Un valor cercano a 0 indica que la distribución de los datos es igual hacia ambos lados (o simétrica) con respecto al promedio. Un valor positivo implica una larga cola hacia la derecha, mientras que un valor negativo significa lo opuesto.
Después de esta sección, revisen la asimetría en los gráficos. La variable pop_living_slums está cerca de 0 (“igualmente” distribuida), poverty_headcount_1.9 es positiva (cola hacia la derecha), y SI.DST.04TH.20 es negativa (cola hacia la izquierda). Cuanto más lejos esté la asimetría de 0, más probable es que la distribución tenga valores atípicos.
kurtosis: describe las colas de la distribución; dicho en términos simples, un número alto puede indicar la presencia de valores atípicos. Para leer un repaso completo de asimetría y curtosis, diríjanse a las Referencias (Skewness and Kurtosis, s. f.) y (Understanding Skewness and Kurtosis, s. f.).iqr: el rango intercuartil es el resultado de observar los percentiles0.25y0.75, e indica, en la misma unidad de la variable, el largo de dispersión del 50% de los valores. Cuanto mayor sea el valor, más dispersa es la variable.range_98yrange_80: indican el rango en el que el se encuentra el98%de los valores. Quita el 1% inferior y superior (ergo, el número98%). Es bueno saber cuál es el rango de la variable sin valores atípicos potenciales. Por ejemplo,pop_living_slumsva de6.83a93.42. Es más robusto que comparar los valores mínimos y máximos.range_80es igual querange_98pero sin el10%inferior y superior.
iqr, range_98 y range_80 están basados en percentiles, que cubriremos más adelante en este capítulo.
Importante: Todas las métricas se calculan quitando los valores NA. De lo contrario, la tabla estaría llena de NAs.
1.1.3.3.1 Consejos para utilizar profiling_num
La idea de la función profiling_num es proveer al científico de datos un conjunto completo de métricas para que pueda seleccionar las más relevantes. Esto se puede hacer fácilmente utilizando pandas.
Por ejemplo, probemos con mean, p_01, p_99 y range_80:
my_profiling_table = profiling_num(data_world_wide)
# Visualizar sólo las primeras tres filas
_c1 = ['variable', 'mean', 'std_dev',
'variation_coef']
_ren_vc = {'variation_coef': 'var_coef'}
print(my_profiling_table[_c1].head(3)
.rename(columns=_ren_vc))
print()
_c2 = ['variable', 'p_01', 'p_05', 'p_25']
print(my_profiling_table[_c2].head(3))
print()
_c3 = ['variable', 'p_50', 'p_75', 'p_95', 'p_99']
print(my_profiling_table[_c3].head(3))
print()
_c4 = ['variable', 'skewness', 'kurtosis', 'iqr']
print(my_profiling_table[_c4].head(3))
print()
_c5 = ['variable', 'range_98', 'range_80']
print(my_profiling_table[_c5].head(3)) variable mean std_dev var_coef
0 SI.DST.02ND.20 10.9403 2.1660 0.1980
1 SI.DST.03RD.20 15.1876 2.0341 0.1339
2 SI.DST.04TH.20 21.4564 1.4916 0.0695
variable p_01 p_05 p_25
0 SI.DST.02ND.20 5.5680 7.3605 9.5275
1 SI.DST.03RD.20 9.1374 11.8275 13.8775
2 SI.DST.04TH.20 16.2861 18.2885 20.7575
variable p_50 p_75 p_95 p_99
0 SI.DST.02ND.20 11.135 12.6125 14.2005 14.5722
1 SI.DST.03RD.20 15.460 16.6975 17.8620 18.1444
2 SI.DST.04TH.20 21.910 22.5225 23.0130 23.3876
variable skewness kurtosis iqr
0 SI.DST.02ND.20 -0.4159 -0.2716 3.085
1 SI.DST.03RD.20 -0.8855 0.9184 2.820
2 SI.DST.04TH.20 -1.5541 2.7388 1.765
variable range_98 range_80
0 SI.DST.02ND.20 [5.57, 14.57] [8.28, 13.8]
1 SI.DST.03RD.20 [9.14, 18.14] [12.67, 17.5]
2 SI.DST.04TH.20 [16.29, 23.39] [19.73, 22.81]Noten que profiling_num devuelve una tabla, por lo que podemos filtrar rápidamente los casos de acuerdo a las condiciones que definamos.
1.1.3.3.2 Analizar variables numéricas utilizando gráficos
Otra función de funpymodeling es plot_num, que toma un conjunto de datos y grafica la distribución de cada variable numérica excluyendo automáticamente las variables no numéricas:
plot_num(data_world_wide)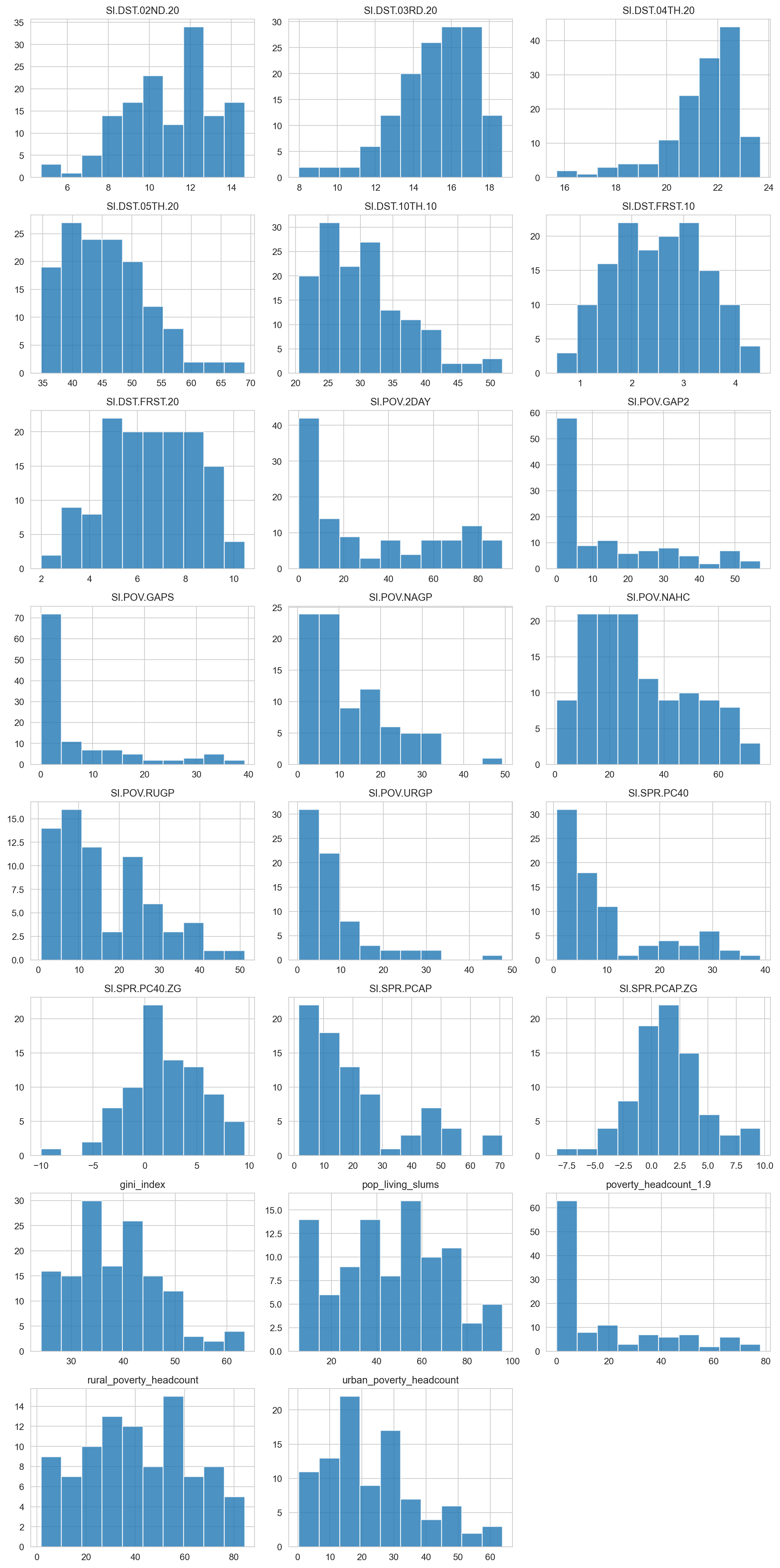
Podemos ajustar la cantidad de barras del gráfico cambiando el parámetro bins (por defecto está configurado en 10). Por ejemplo: plot_num(data_world_wide, bins=20).
1.1.4 Reflexiones finales
Hasta aquí, han aparecido muchos números, y aún más en el apéndice de percentiles. Lo importante es que encuentren el enfoque adecuado para explorar sus datos. Puede estar relacionado con las métricas o con otros criterios.
Las funciones status, describe, freq_tbl, profiling_num y plot_num pueden ejecutarse al principio de un proyecto de datos.
Con respecto al comportamiento normal y anormal de los datos, es importante estudiar ambos. Para describir un conjunto de datos en términos generales, deberíamos excluir los valores extremos: por ejemplo, con la variable range_98. El promedio debería disminuir después de la exclusión.
Estos análisis son univariados; es decir, no tienen en cuenta otras variables (análisis multivariado). Esto estará incluido en este libro más adelante. Mientras tanto, para encontrar la correlación entre variables ingresadas (y de resultados), pueden dirigirse al capítulo de Correlación.
![]()
1.2 Correlación y relación

Fractal de Mandelbrot, donde el caos expresa su belleza; fuente de la imagen: Wikipedia.
1.2.1 ¿De qué se trata esto?
Este capítulo contiene aspectos metodológicos y prácticos de la medición de correlación en variables. Veremos que la palabra correlación puede traducirse en “relación funcional”.
En metodología encontrarán el Cuarteto de Anscombe, un conjunto de cuatro gráficos con distribuciones espaciales diferentes, pero que comparten la misma medida de correlación. Iremos un paso más allá recalculando su relación a través de una métrica más robusta (Coeficiente de Información Máxima o MIC, por sus siglas en inglés).
Mencionaremos Teoría de la Información varias veces; aunque por ahora la cubriremos a nivel matemático, está previsto hacerlo. Muchos algoritmos se basan en ella, incluso el aprendizaje profundo (deep learning).
Entender estos conceptos en dimensiones bajas (dos variables) y datos pequeños (un grupo de filas) nos permite entender mejor los datos de alta dimensión. No obstante, algunos casos reales son sólo datos pequeños.
Desde el punto de vista práctico, podrán replicar el análisis con sus propios datos, analizando numéricamente y exponiendo sus relaciones en gráficos sofisticados.
Empecemos por cargar todas las bibliotecas que necesitaremos.
# (Bibliotecas ya cargadas al inicio del capítulo)
np.set_printoptions(suppress=True)1.2.2 Correlación lineal
Quizás la medida de correlación más estándar para las variables numéricas es la R statistic (o coeficiente de Pearson) que va desde 1 correlación positiva hasta -1 correlación negativa. Un valor alrededor de 0 implica que no hay correlación.
Consideren el ejemplo siguiente, que calcula la medida R basada en una variable de destino (por ejemplo, para realizar la feature engineering). En pandas, podemos usar el método corr() para obtener la métrica R de todas las variables numéricas omitiendo las categóricas/nominales.
# Calcular correlación con la variable objetivo usando pandas
correlation_result = (
heart_disease
.corr(numeric_only=True)['has_heart_disease']
.sort_values(ascending=False))
print(correlation_result)has_heart_disease 1.000000
thal 0.525689
ca 0.460442
exer_angina 0.431894
oldpeak 0.424510
chest_pain 0.414446
slope 0.339213
sex 0.276816
age 0.223120
resting_ecg 0.169202
resting_blood_pressure 0.150825
serum_cholesterol 0.085164
fasting_blood_sugar 0.025264
max_heart_rate -0.417167
Name: has_heart_disease, dtype: float64La variable thal es una de las variables -tratada como numérica- más importantes; cuanto mayor sea su valor, mayores serán las probabilidades de padecer una enfermedad cardíaca (correlación positiva). Lo contrario de max_heart_rate, que tiene una correlación negativa.
Al elevar este número al cuadrado obtenemos la estadística R-squared (también conocida como R cuadrado o R2), que va desde 0 no hay correlación hasta 1 alta correlación.
El estadístico R está profundamente influenciado por los valores atípicos y las relaciones no lineales.
1.2.2.1 Correlación en el Cuarteto de Anscombe
Observen el Cuarteto de Anscombe, citando a Wikipedia:
Fueron construidos en 1973 por el estadístico Francis Anscombe para demostrar tanto la importancia de graficar los datos antes de analizarlos como el efecto de los valores atípicos sobre las propiedades estadísticas.
1973 y sigue vigente hoy, es fantástico.
Estas cuatro relaciones son diferentes, pero todas tienen la misma R2: ~0.67.
El siguiente ejemplo calcula el R2 y grafica cada par.
anscombe_url = ("https://raw.githubusercontent.com/pablo14/"
"data-science-live-book/master/"
"exploratory_data_analysis/anscombe_quartet.txt")
anscombe_data = pd.read_csv(anscombe_url, sep="\t")
# R2 para cada par
cors = [pearsonr(anscombe_data[f'x{i}'], anscombe_data[f'y{i}'])[0] for i in range(1, 5)]
print(f"R2 para cada par: {', '.join(f'{c**2:.3f}' for c in cors)}")
def plot_anscombe(x, y, value, label, ax):
sns.regplot(x=x, y=y, data=anscombe_data, ax=ax, ci=None,
scatter_kws={'s': 50, 'alpha': 0.7}, line_kws={'color': 'red', 'alpha': 0.8})
ax.set(xlim=(4, 19), ylim=(2, 13))
ax.text(12, 4.5, f'{label}: {value:.2f}', fontsize=14, fontweight='bold')
fig, axes = plt.subplots(2, 2, figsize=(8, 7))
for i, ax in enumerate(axes.flat):
plot_anscombe(f'x{i+1}', f'y{i+1}', cors[i]**2, 'R2', ax)
plt.tight_layout(); plt.show()R2 para cada par: 0.667, 0.666, 0.666, 0.667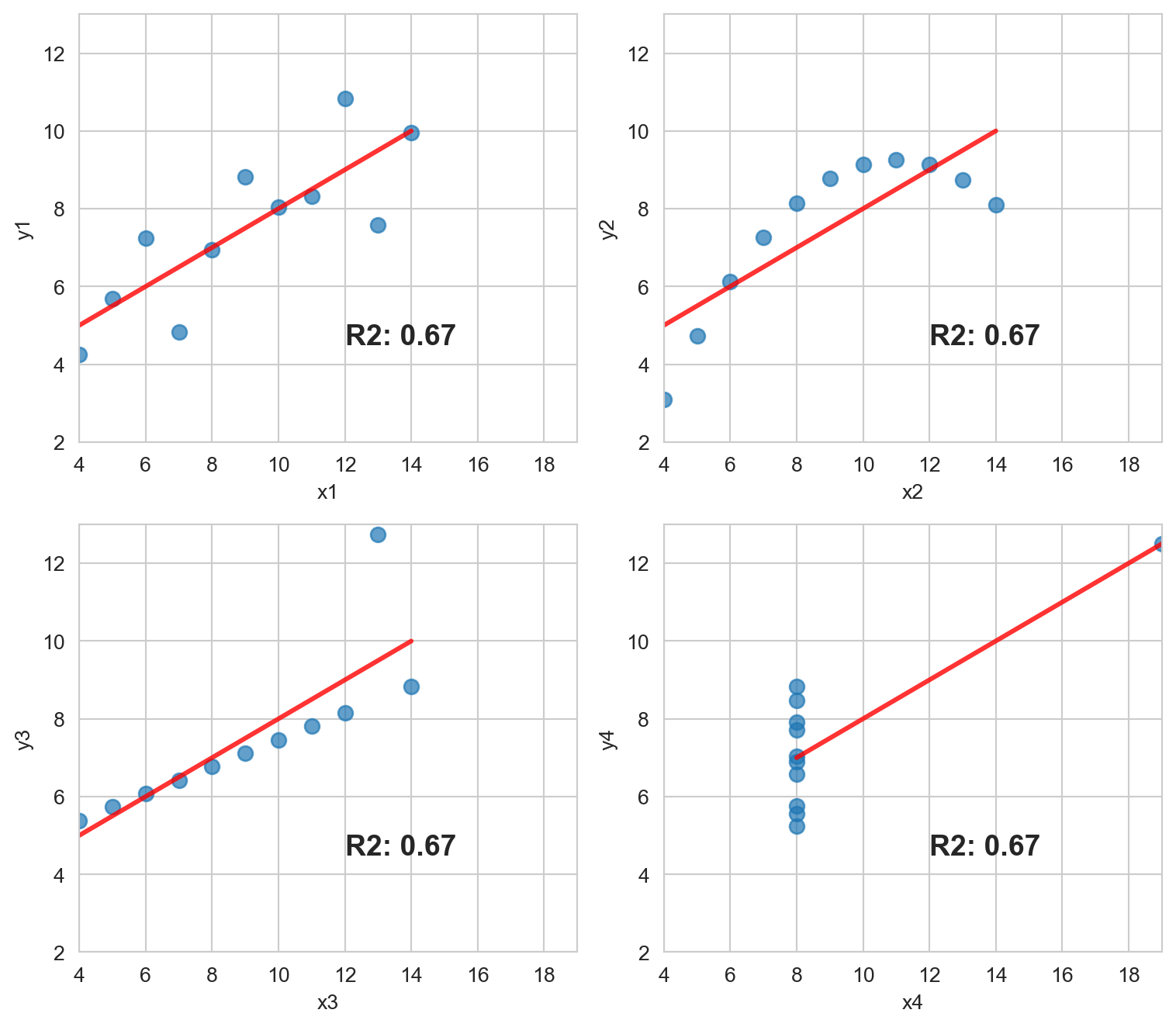
4 gráficos diferentes, con el mismo mean para cada variable x y y (9 y 7.501, respectivamente), y el mismo grado de correlación. Pueden comprobar todas las medidas con anscombe_data.describe().
Por esto es tan importante graficar relaciones cuando se analizan las correlaciones.
Volveremos sobre estos datos más tarde. ¡Se pueden mejorar! Primero, introduciremos algunos conceptos de la Teoría de la Información.
1.2.3 Correlación basada en la Teoría de la Información
Estas relaciones pueden medirse mejor con conceptos de la Teoría de la Información. Uno de los muchos algoritmos que se utilizan para medir la correlación basada en esto es MINE, una sigla que significa Maximal Information-based nonparametric exploration, en inglés.
Pueden encontrar la implementación en Python en el paquete minepy. También está disponible en otros lenguajes, como R.
1.2.3.1 Ejemplo en Python: Una relación perfecta
Grafiquemos una relación no lineal, basada directamente en una función (exponencial negativa), y visualicemos el valor MIC.
x = np.linspace(0, 20, 500)
df_exp = pd.DataFrame({'x': x, 'y': stats.expon.pdf(x, scale=1/0.65)})
plt.figure(figsize=(7, 4))
plt.plot(df_exp['x'], df_exp['y'], color='steelblue', linewidth=2)
plt.grid(True, alpha=0.3); plt.show()
print(f"R2: {pearsonr(df_exp['x'], df_exp['y'])[0]**2:.2f}")
print(f"MIC: {calc_mic(df_exp['x'].values, df_exp['y'].values):.3f}")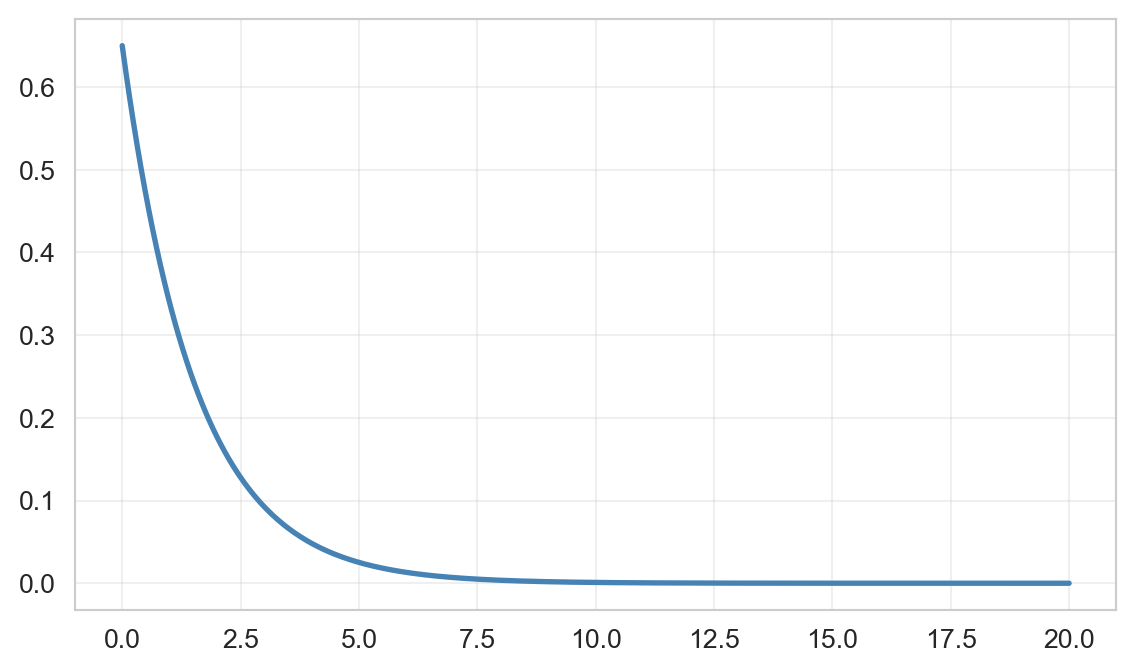
R2: 0.39
MIC: 1.874Los valores de MIC van de 0 a 1. Cuando es 0, implica que no hay correlación y 1 implica la mayor correlación posible. La interpretación de los valores es la misma que para R cuadrado.
1.2.3.2 Análisis de los resultados
MIC=1 indica que hay una correlación perfecta entre dos variables. Si estamos haciendo feature engineering debemos incluir esta variable.
Más que una simple correlación, lo que dice el MIC es: “Hey, estas dos variables muestran una relación funcional”.
En términos de machine learning (y simplificando demasiado): “la variable y es dependiente de la variable x y una función -no sabemos cuál- puede ser un modelo de la relación entre ellas.”
Esto es delicado porque esa relación fue efectivamente creada a partir de una función, una exponencial.
Pero continuemos con otros ejemplos…
1.2.4 Agregar ruido
El ruido es una señal no deseada que se suma a la original. En machine learning, el ruido contribuye a que el modelo se confunda. En concreto: dos casos idénticos son ingresados -por ejemplo, clientes- y tienen resultados diferentes -uno compra y el otro no.
Ahora vamos a añadir algo de ruido creando la variable y_noise_1.
np.random.seed(42)
df_exp['y_noise_1'] = df_exp['y'] + np.random.normal(0, df_exp['y'].std() * 0.5, len(df_exp))
plt.figure(figsize=(7, 4))
plt.plot(df_exp['x'], df_exp['y_noise_1'], color='steelblue', linewidth=1, alpha=0.7)
plt.grid(True, alpha=0.3); plt.show()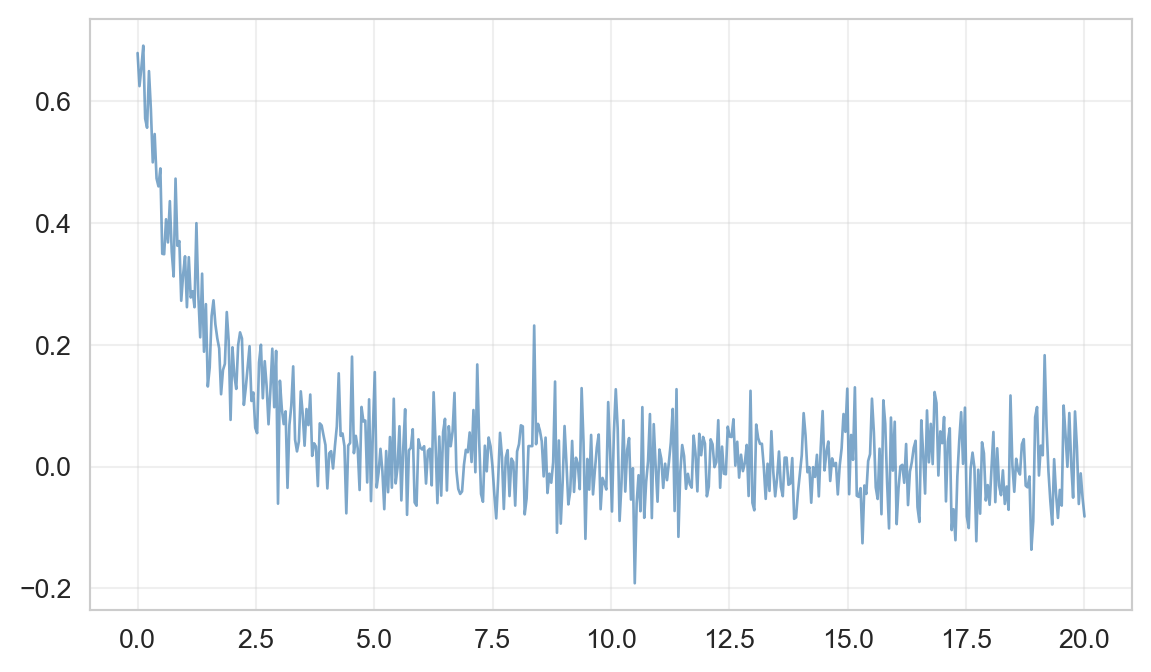
Calculando de nuevo la correlación y el MIC, visualizando en ambos casos la matriz completa, que muestra la métrica de correlación/MIC de cada variable de entrada con respecto a todas las demás, incluidas ellas mismas.
xv, yv, ynv = df_exp['x'].values, df_exp['y'].values, df_exp['y_noise_1'].values
r2_orig, r2_noise = pearsonr(xv, yv)[0]**2, pearsonr(xv, ynv)[0]**2
mic_orig, mic_noise = calc_mic(xv, yv), calc_mic(xv, ynv)
print(f"R2 original: {r2_orig:.7f} | R2 con ruido: {r2_noise:.7f}")
print(f"MIC original: {mic_orig:.3f} | MIC con ruido: {mic_noise:.3f}")
print(f"Cambio MIC: {(mic_noise - mic_orig) / mic_orig * 100:.1f}%")
print(f"Cambio R2: {(r2_noise - r2_orig) / r2_orig * 100:.1f}%")R2 original: 0.3899148 | R2 con ruido: 0.3151549
MIC original: 1.874 | MIC con ruido: 0.447
Cambio MIC: -76.1%
Cambio R2: -19.2%Al agregar ruido a los datos, el valor de MIC disminuye significativamente, ¡y eso es genial!
R2 también disminuyó, pero en menor proporción.
Conclusión: El MIC refleja una relación ruidosa mucho mejor que R2, y nos ayuda a encontrar asociaciones correlacionadas.
Sobre el último ejemplo: Generar datos basándonos en una función solamente sirve para fines educativos. Pero el concepto de ruido en variables es bastante común casi todos los conjuntos de datos, sin importar su fuente. No tienen que hacer nada para agregar ruido a las variables, ya está ahí. Los modelos de machine learning lidian con este ruido aproximándose a la forma real de los datos.
Es bastante útil usar la medición del MIC para tener una idea de la información presente en la relación entre dos variables.
1.2.5 Midiendo la no linealidad (MIC-R2)
La función mine devuelve varias métricas, sólo observamos MIC, pero dada la naturaleza del algoritmo (pueden referirse al paper original (Reshef et al. 2011)), puede computar indicadores mucho más interesantes. Pueden examinarlos todos en el objeto mine.
Uno de ellos es MICR2, que se utiliza como una medida de no linealidad. Se calcula haciendo: MIC - R2. Como R2 mide la linealidad, un alto MICR2 indicaría una relación no lineal.
Podemos verificarlo calculando el MICR2 manualmente, las dos matrices a continuación devuelven el mismo resultado:
# calc_mic_r2 ya calcula MIC - R2 directamente
micr2 = calc_mic_r2(df_exp['x'].values, df_exp['y_noise_1'].values)
print(f"MIC-R2: {micr2:.3f}")MIC-R2: 0.132Las relaciones no lineales son más complejas para construir modelos, sobre todo utilizando un algoritmo lineal como árboles de decisión o regresión lineal.
Imaginen que debemos explicar la relación a otra persona, necesitaremos “más palabras” para hacerlo. Es más fácil decir: “A aumenta mientras B disminuye y el coeficiente siempre es 3x” (si A=1 entonces B=3, lineal).
En comparación con: “A aumenta mientras B disminuye, pero A es casi 0 hasta que B alcanza el valor 10, entonces A aumenta a 300; y cuando B alcanza 15, A llega a 1000.”
df_example = pd.DataFrame({'x': df_exp['x'], 'y_exp': df_exp['y'], 'y_linear': 3 * df_exp['x'] + 2})
xv = df_example['x'].values
mic_exp, micr2_exp = calc_mic(xv, df_example['y_exp'].values), calc_mic_r2(xv, df_example['y_exp'].values)
mic_lin, micr2_lin = calc_mic(xv, df_example['y_linear'].values), calc_mic_r2(xv, df_example['y_linear'].values)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.plot(df_example['x'], df_example['y_exp'], color='steelblue')
ax1.set(xlabel='x', ylabel='y_exp')
ax1.text(10, 0.4, f'MIC: {mic_exp:.3f}\nMIC-R2 (non-linearity): {micr2_exp:.3f}', fontsize=9)
ax2.plot(df_example['x'], df_example['y_linear'], color='steelblue')
ax2.set(xlabel='x', ylabel='y_linear')
ax2.text(7, 55, f'MIC: {mic_lin:.3f}\nMIC-R2 (non-linearity): {micr2_lin:.3f}', fontsize=9)
plt.tight_layout(); plt.show()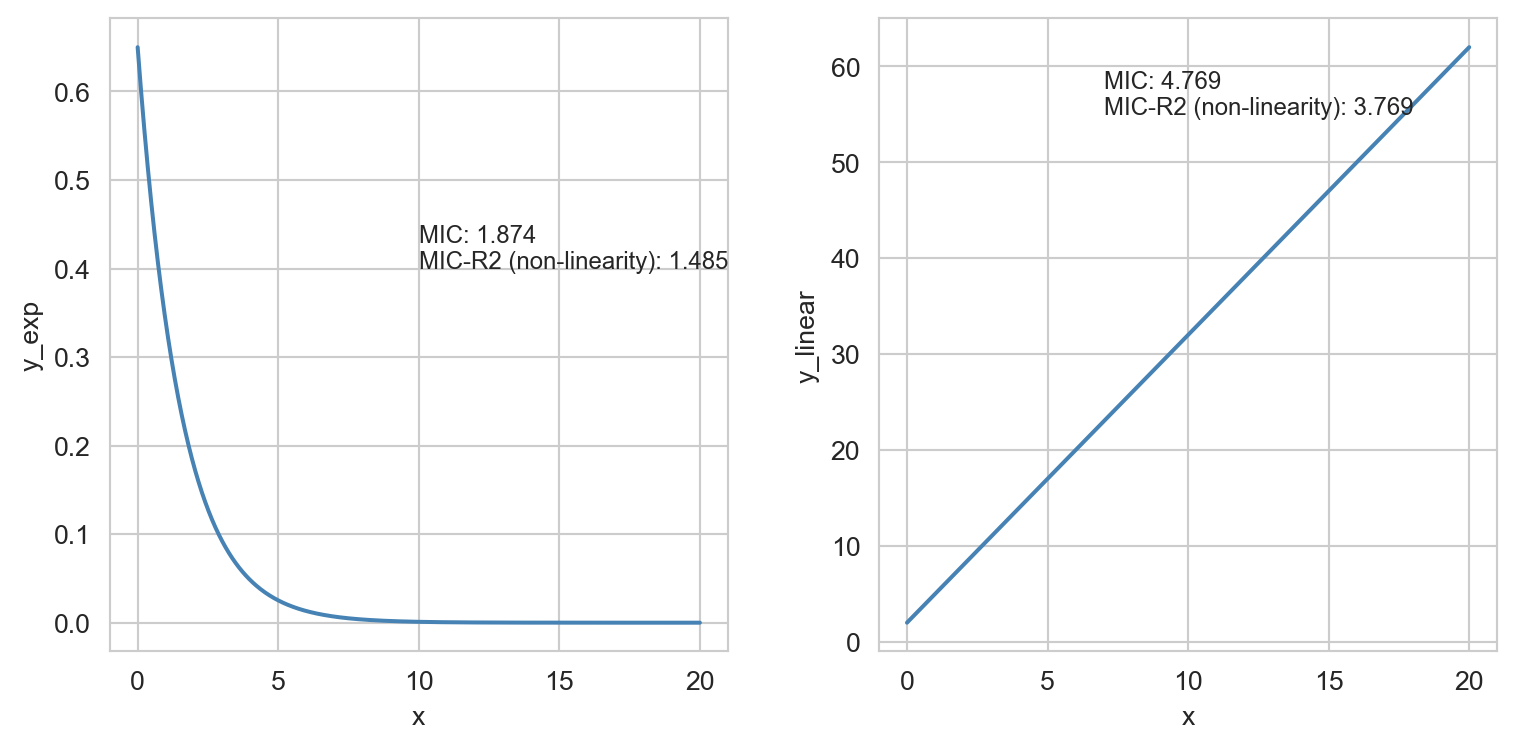
Ambos gráficos muestran una correlación (o relación) perfecta, con MIC=1. Con respecto a la no linealidad, MICR2 se comporta como era esperado, en y_exp~0.61, y en y_linear=0.
Este punto es importante dado que MIC se comporta como R2 en relaciones lineales, además se adapta bastante bien a relaciones no lineales como vimos antes, obteniendo una métrica de puntuación particular (MICR2) para analizar la relación.
1.2.6 Medir información en el Cuarteto de Anscombe
¿Recuerdan el ejemplo que revisamos al principio? Cada par del Cuarteto de Anscombe devuelve un R2 de ~0.67. Pero basándonos en los gráficos estaba claro que no todos los pares exhiben ni una buena correlación ni una distribución similar de x y y.
Pero, ¿qué pasa si medimos la relación con una métrica basada en la Teoría de la Información? Sí, otra vez MIC.
# calc_mic ya definido al inicio del capítulo, usamos alpha=0.8 para muestras pequeñas
mics = [calc_mic(anscombe_data[f'x{i}'].values, anscombe_data[f'y{i}'].values, alpha=0.8) for i in range(1, 5)]
fig, axes = plt.subplots(2, 2, figsize=(8, 7))
for i, ax in enumerate(axes.flat):
plot_anscombe(f'x{i+1}', f'y{i+1}', mics[i], 'MIC', ax)
plt.tight_layout(); plt.show()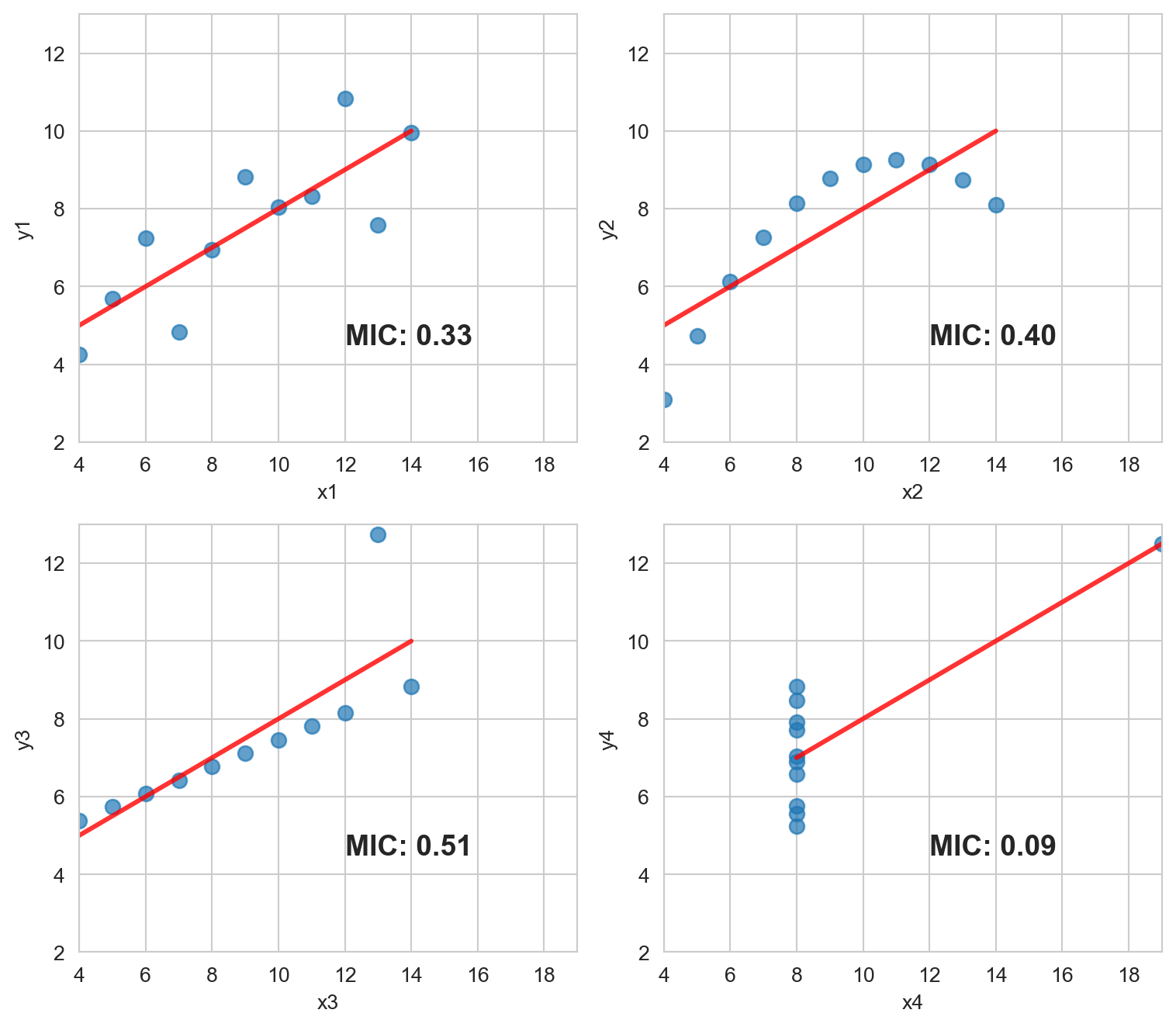
Como habrán notado, aumentamos el valor de alpha a 0.8, esto es una buena práctica -de acuerdo a la documentación- cuando analizamos muestras pequeñas. El valor por defecto es 0.6 y el máximo es 1.
En este caso, el valor de MIC detectó la relación más espuria en el par x4 - y4. Probablemente debido a unos pocos casos por gráfico (11 filas) el MIC fue el mismo para todos los otros pares. Tener más casos se reflejará en diferentes valores de MIC.
Pero cuando se combina el MIC con MIC-R2 (medida de no linealidad) aparecen nuevas perspectivas:
# calc_mic_r2 ya definido al inicio del capítulo
mic_r2s = [calc_mic_r2(anscombe_data[f'x{i}'].values, anscombe_data[f'y{i}'].values, alpha=0.8) for i in range(1, 5)]
df_mic_r2 = pd.DataFrame({'pair': range(1, 5), 'mic_r2': mic_r2s}).sort_values('mic_r2', ascending=False)
print(df_mic_r2) pair mic_r2
2 3 -0.155141
1 2 -0.263248
0 1 -0.337574
3 4 -0.575546Al ordenarlos de manera decreciente según su no linealidad los resultados son consistentes con los gráficos. Ocurre algo llamativo en el par 4, un número negativo. Esto se debe a que el MIC es inferior al R2. Una relación que merece ser graficada.
1.2.7 Midiendo la no-monotonicidad: medida MAS
MINE también nos puede ayudar a analizar numéricamente series temporales con respecto a su no-monotonicidad con MAS (puntaje de asimetría máxima).
Una serie monótona es aquella que nunca cambia su tendencia, siempre es creciente o decreciente. Encontrarán más información sobre esto en (Monotonic function, s. f.).
El siguiente ejemplo simula dos series temporales, una no-monótona y_1 y una monótona y_2.
np.random.seed(0)
time_x = np.sort(np.random.uniform(0, 1, 1000))
y_1, y_2 = 4 * (time_x - 0.5)**2, 4 * (time_x - 0.5)**3
mas_y1, mas_y2 = round(calc_mas(time_x, y_1), 2), round(calc_mas(time_x, y_2), 2)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.plot(time_x, y_1, color='steelblue')
ax1.text(0.45, 0.75, f'MAS={mas_y1} (baja y sube\n=> no-monótona)', fontsize=9)
ax1.set(xlabel='time_x', ylabel='y_1')
ax2.plot(time_x, y_2, color='steelblue')
ax2.text(0.43, 0.35, f'MAS={mas_y2} (sube => monótona)', fontsize=9)
ax2.set(xlabel='time_x', ylabel='y_2')
plt.tight_layout()
plt.show()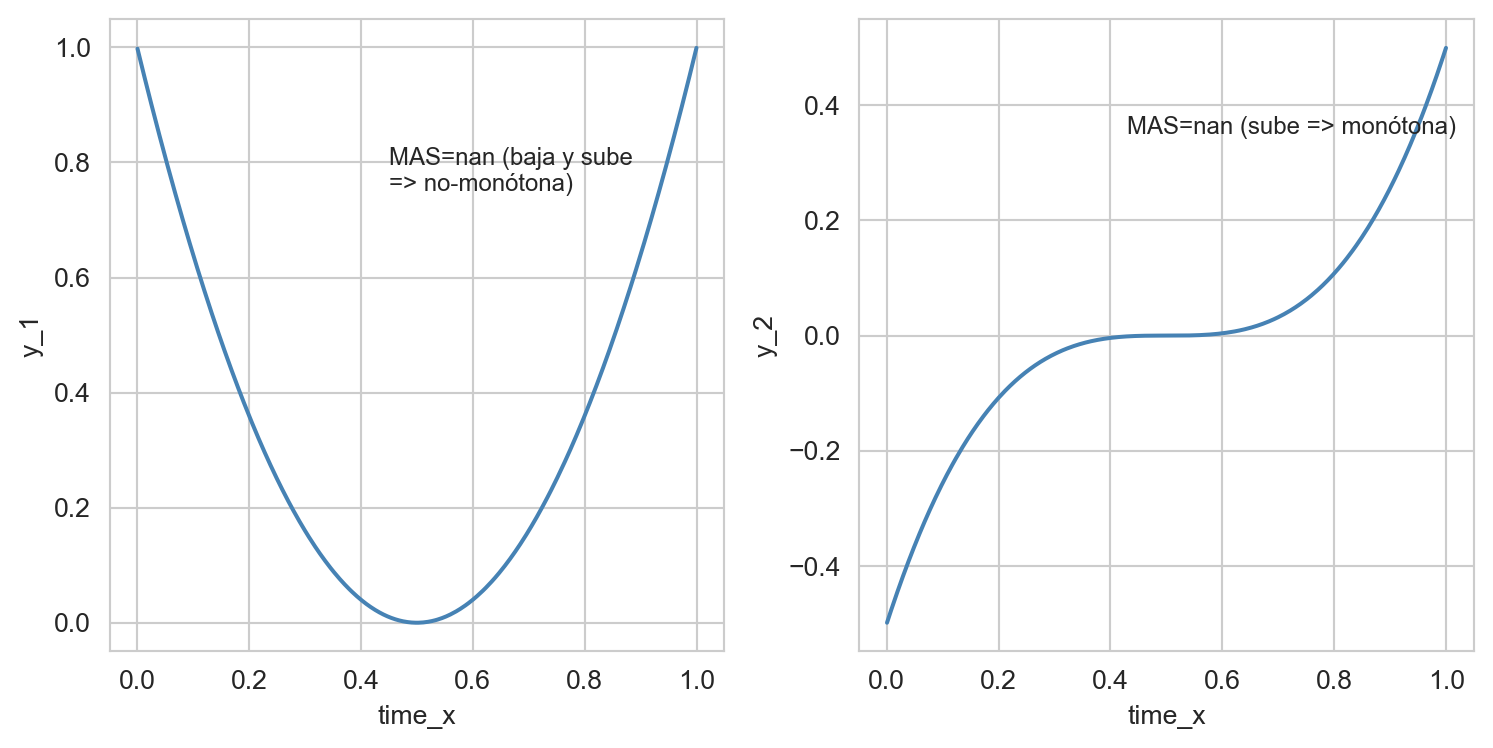
Desde otra perspectiva, el MAS también es útil para detectar relaciones periódicas. Ilustremos esto con un ejemplo:
x_per = np.arange(-2*np.pi, 2*np.pi, 0.2)
df_per = pd.DataFrame({'x': x_per, 'y': np.sin(2*x_per)})
x_non_per = np.arange(1, 101)
df_non_per = pd.DataFrame({'x': x_non_per, 'y': 2*x_non_per**2 + 2})
mas_per = round(calc_mas(df_per['x'].values, df_per['y'].values), 2)
mas_non = round(calc_mas(df_non_per['x'].values, df_non_per['y'].values), 2)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.plot(df_per['x'], df_per['y'], color='steelblue')
ax1.set_title(f'MAS={mas_per} (periódica)')
ax2.plot(df_non_per['x'], df_non_per['y'], color='steelblue')
ax2.set_title(f'MAS={mas_non} (no periódica)')
plt.tight_layout(); plt.show()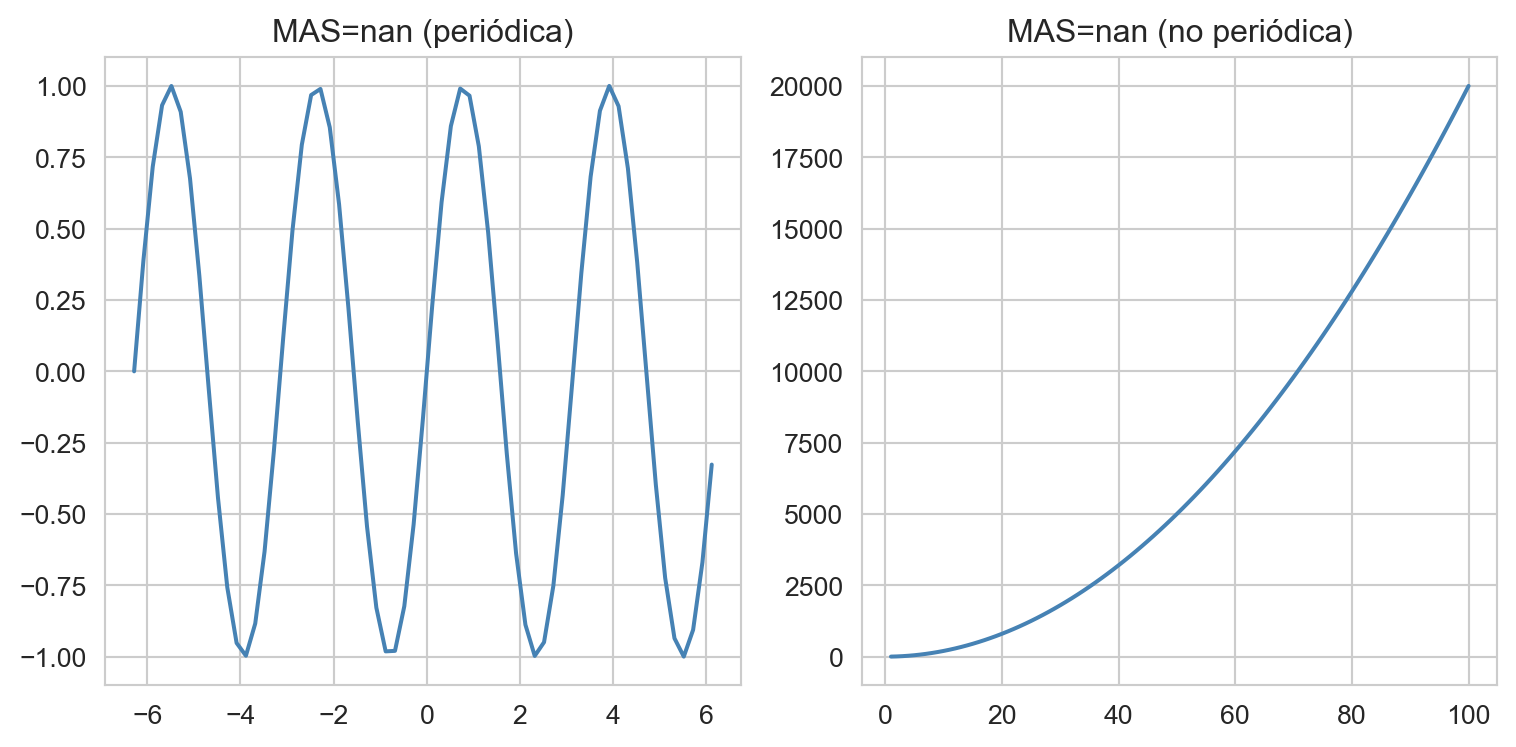
1.2.7.1 Un ejemplo más real: Series Temporales
Consideren el siguiente caso que contiene tres series temporales: “y1”, “y2” y “y3”. Se pueden analizar numéricamente en cuanto a su no-monotonicidad o a la tendencia general de crecimiento.
_url_ts = (
"https://raw.githubusercontent.com/pablo14/"
"data-science-live-book/master/"
"exploratory_data_analysis/df_time.txt")
df_time_series = pd.read_csv(_url_ts, sep="\t")
df_time_series_long = df_time_series.melt(id_vars='time', var_name='variable', value_name='value')
plt.figure(figsize=(7, 4))
for var in ['y1', 'y2', 'y3']:
sub = df_time_series_long[df_time_series_long['variable'] == var]
plt.plot(sub['time'], sub['value'], label=var)
plt.legend(); plt.grid(True, alpha=0.3); plt.show()
for col in ['y1', 'y2', 'y3']:
print(f"MAS (time vs {col}): {calc_mas(df_time_series['time'].values, df_time_series[col].values):.3f}")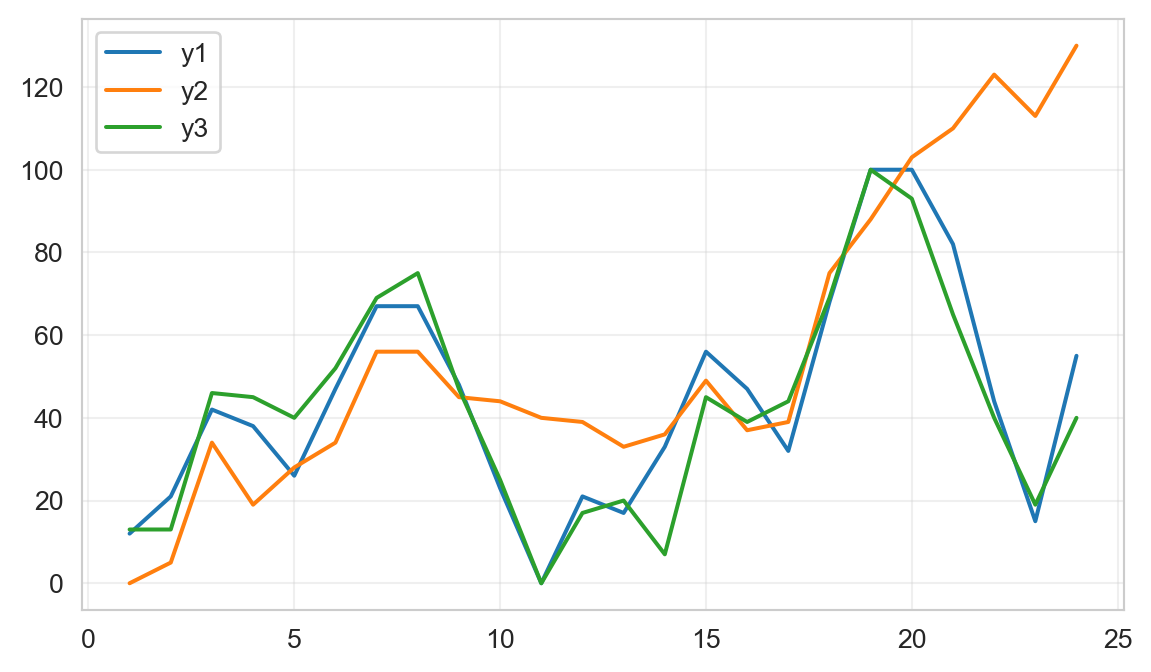
MAS (time vs y1): nan
MAS (time vs y2): nan
MAS (time vs y3): nanNecesitamos mirar la columna de “tiempo”, así tendremos el valor de MAS de cada serie con respecto al tiempo. y2 es la serie más monótona (y menos periódica), y podemos confirmarlo mirándola. Parece que siempre es ascendente.
Resumen de MAS:
- MAS ~ 0 indica una función monótona o no periódica (“siempre” ascendente o descendente)
- MAS ~ 1 indica una función no-monótona o periódica
1.2.8 Correlación entre series temporales
La métrica MIC también puede medir la correlación en series temporales, no es una herramienta de uso general pero puede ser útil para comparar diferentes series rápidamente.
Esta sección se basa en los mismos datos que usamos en el ejemplo de MAS.
plt.figure(figsize=(7, 4))
for var in ['y1', 'y2', 'y3']:
sub = df_time_series_long[df_time_series_long['variable'] == var]
plt.plot(sub['time'], sub['value'], label=var)
plt.legend(); plt.grid(True, alpha=0.3); plt.show()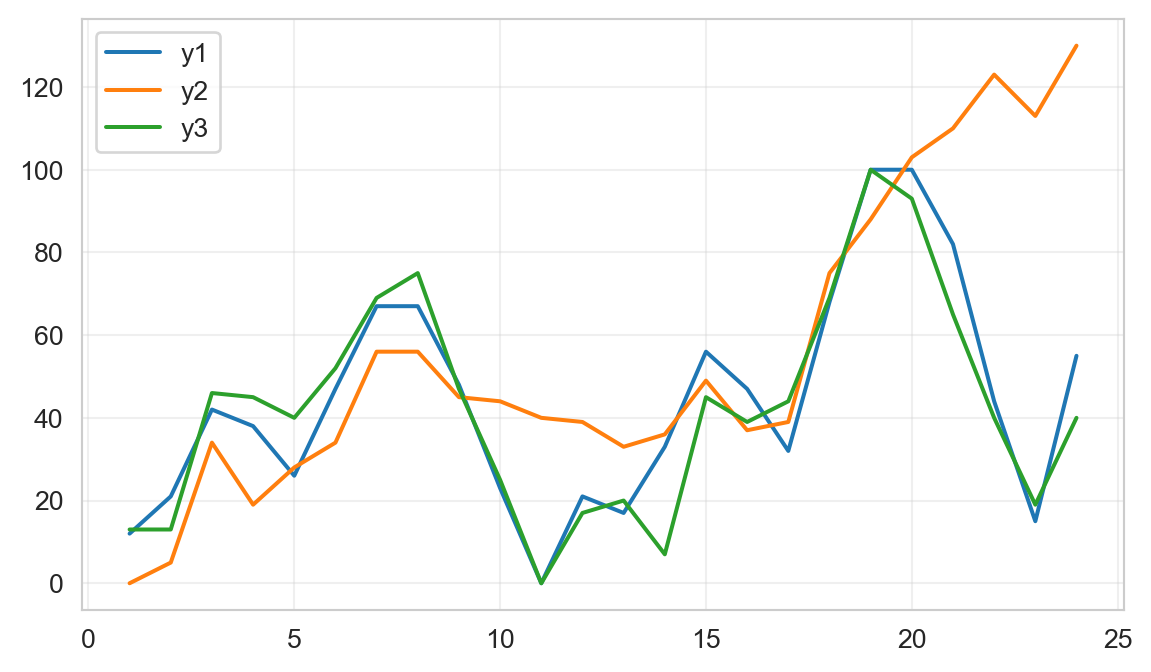
cols = ['y1', 'y2', 'y3']
mic_matrix = pd.DataFrame(
{i: {j: round(calc_mic(df_time_series[i].values, df_time_series[j].values), 3)
for j in cols} for i in cols})
print(mic_matrix) y1 y2 y3
y1 1.866 0.274 0.956
y2 0.269 1.873 0.024
y3 0.913 0.023 1.842Ahora tenemos que mirar la columna y1. De acuerdo con la medición del MIC, podemos confirmar lo mismo que se muestra en el último gráfico:
y1 es más parecido a y3 (MIC=0.709) que a y2 (MIC=0.617).
1.2.8.1 Yendo más allá: Deformación dinámica del tiempo
El MIC no servirá en escenarios más complejos que tengan series temporales que varíen en velocidad, utilizaremos la técnica de deformación dinámica del tiempo (DTW, en inglés).
Usemos una imagen para acercarnos al concepto visualmente:

Fuente de la imagen: Deformación dinámica del tiempo Convirtiendo imágenes en series temporales para data mining (Lin et al. 2007).
La última imagen muestra dos enfoques diferentes para comparar series temporales, y el euclídeo es más similar a la medición del MIC. Mientras que la Deformación dinámica del tiempo puede rastrear las similitudes que ocurren en diferentes momentos.
Una linda implementación en Python: dtaidistance.
Encontrar correlaciones entre series temporales es otra forma de agrupar series temporales.
1.2.9 Correlación en variables categóricas
MINE -y muchos otros algoritmos- sólo funcionan con datos numéricos. Tenemos que hacer un truco de preparación de datos, convirtiendo cada variable categórica en un flag (o variable dummy).
Si la variable categórica original tiene 30 valores posibles, como resultado tendremos 30 nuevas columnas con valor 0 o 1, donde 1 representa la presencia de esa categoría en la fila.
Si usamos pd.get_dummies de pandas, esta conversión sólo requiere dos líneas de código:
heart_disease_2 = heart_disease[['max_heart_rate', 'oldpeak', 'thal', 'chest_pain',
'exer_angina', 'has_heart_disease']].copy()
heart_disease_2['has_heart_disease'] = heart_disease_2['has_heart_disease'].astype(int)
heart_disease_3 = pd.get_dummies(heart_disease_2, columns=['thal', 'chest_pain', 'exer_angina'],
drop_first=False, dtype=int)
heart_disease_3.columns = [c.replace('thal_', 'thal.').replace('chest_pain_', 'chest_pain.')
.replace('exer_angina_', 'exer_angina.') for c in heart_disease_3.columns]
heart_disease_4 = heart_disease_3.dropna()
# Matriz MIC completa usando calc_mic
cols_hd = heart_disease_4.columns.tolist()
n_hd = len(cols_hd)
mine_res_hd_mic = pd.DataFrame(np.zeros((n_hd, n_hd)), index=cols_hd, columns=cols_hd)
for i in range(n_hd):
for j in range(i, n_hd):
val = round(calc_mic(heart_disease_4[cols_hd[i]].values,
heart_disease_4[cols_hd[j]].values), 7)
mine_res_hd_mic.iloc[i, j] = mine_res_hd_mic.iloc[j, i] = valVisualizando una muestra…
with pd.option_context('display.width', 72):
print(mine_res_hd_mic.iloc[:5, :5].round(4)) max_heart_rate oldpeak has_heart_disease \
max_heart_rate 4.0092 0.1251 0.0603
oldpeak 0.1251 2.7578 0.1160
has_heart_disease 0.0603 0.1160 0.6886
thal.3.0 0.1321 0.1076 0.1544
thal.6.0 0.0000 0.0497 0.0000
thal.3.0 thal.6.0
max_heart_rate 0.1321 0.0000
oldpeak 0.1076 0.0497
has_heart_disease 0.1544 0.0000
thal.3.0 0.6929 0.0567
thal.6.0 0.0567 0.2483 Donde la columna thal.3 toma un valor de 1 cuando thal=3.0.
1.2.9.1 ¡Visualizamos unos sofisticados gráficos!
Utilizaremos seaborn que puede graficar una matriz de correlación clásica, o cualquier otra matriz. Graficaremos la matriz MIC en este caso, pero también se puede usar cualquier otra, por ejemplo, MAS o cualquier otra métrica que devuelva una matriz cuadrada de correlaciones.
Los dos gráficos se basan en los mismos datos pero muestran la correlación de distintas formas.
mic_plot = mine_res_hd_mic.copy()
np.fill_diagonal(mic_plot.values, 0)
n = len(mic_plot)
mask_upper = np.triu(np.ones((n, n), dtype=bool))
# Gráfico 1: círculos proporcionales al MIC
fig, ax = plt.subplots(figsize=(7, 7))
cmap, norm = plt.cm.PuOr, Normalize(vmin=0, vmax=mic_plot.values.max())
for i in range(n):
for j in range(i):
val = mic_plot.iloc[i, j]
ax.scatter(j, i, s=max(val / mic_plot.values.max() * 500, 5),
c=[cmap(norm(val))], edgecolors='lightgray', linewidths=0.3)
ax.set_xticks(range(n)); ax.set_yticks(range(n))
ax.set_xticklabels(mic_plot.columns, rotation=90, fontsize=7, color='red')
ax.set_yticklabels(mic_plot.index, fontsize=7, color='red')
ax.set(xlim=(-0.5, n-0.5), ylim=(n-0.5, -0.5), aspect='equal')
sm = ScalarMappable(cmap=cmap, norm=norm); sm.set_array([])
plt.colorbar(sm, ax=ax, shrink=0.6); plt.tight_layout(); plt.show()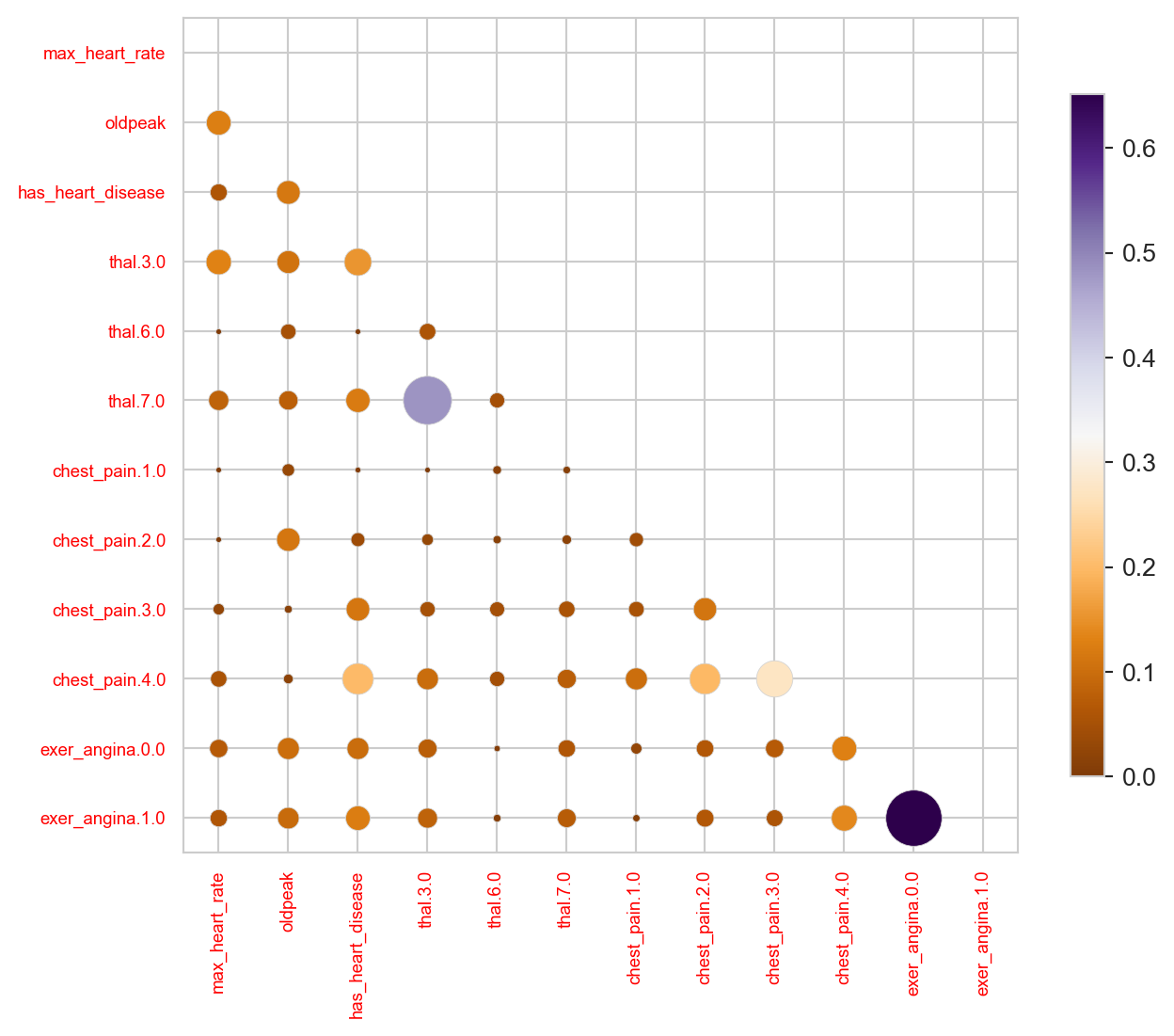
# Gráfico 2: heatmap con valores MIC
fig, ax = plt.subplots(figsize=(7, 7))
sns.heatmap(mic_plot, mask=mask_upper, annot=True, fmt='.2f', cmap='Blues',
square=True, linewidths=0.5, vmin=0, cbar_kws={"shrink": 0.6},
annot_kws={'size': 7, 'color': 'black'})
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, fontsize=7, color='red')
ax.set_yticklabels(ax.get_yticklabels(), rotation=0, fontsize=7, color='red')
plt.tight_layout(); plt.show()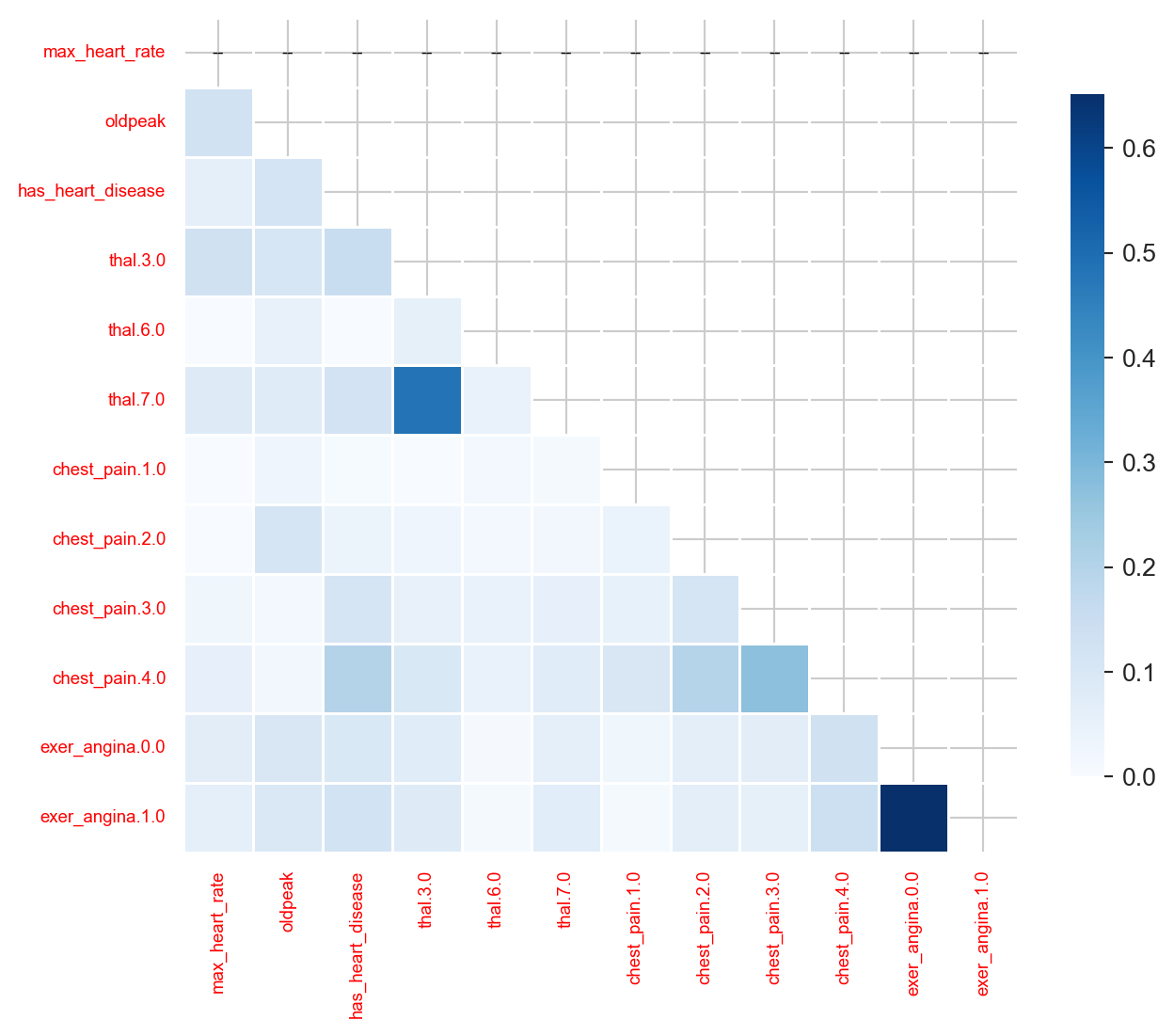
Simplemente cambien la matriz MIC por la que quieran y reutilicen el código con sus datos.
1.2.9.2 Un comentario sobre este tipo de gráficos
Sólo son útiles cuando no hay un gran número de variables. O si primero hacen una selección de variables, teniendo en cuenta que todas deben ser numéricas.
Si hay alguna variable categórica en la selección, pueden convertirla primero en numérica e inspeccionar la relación entre las variables, para ver cómo ciertos valores de las variables categóricas están más relacionados con ciertos resultados, como en este caso.
1.2.9.3 ¿Qué tal si sacamos algunas conclusiones de los gráficos?
Como la variable a predecir es has_heart_disease, aparece algo interesante: tener una enfermedad cardíaca está más correlacionado con thal=3 que con el valor thal=6.
El mismo análisis aplica para la variable chest_pain, un valor de 4 es más peligroso que un valor de 1.
Y podemos comprobarlo con otro gráfico:
cross_plot(heart_disease, input='chest_pain',
target='has_heart_disease', plot_type='percentual')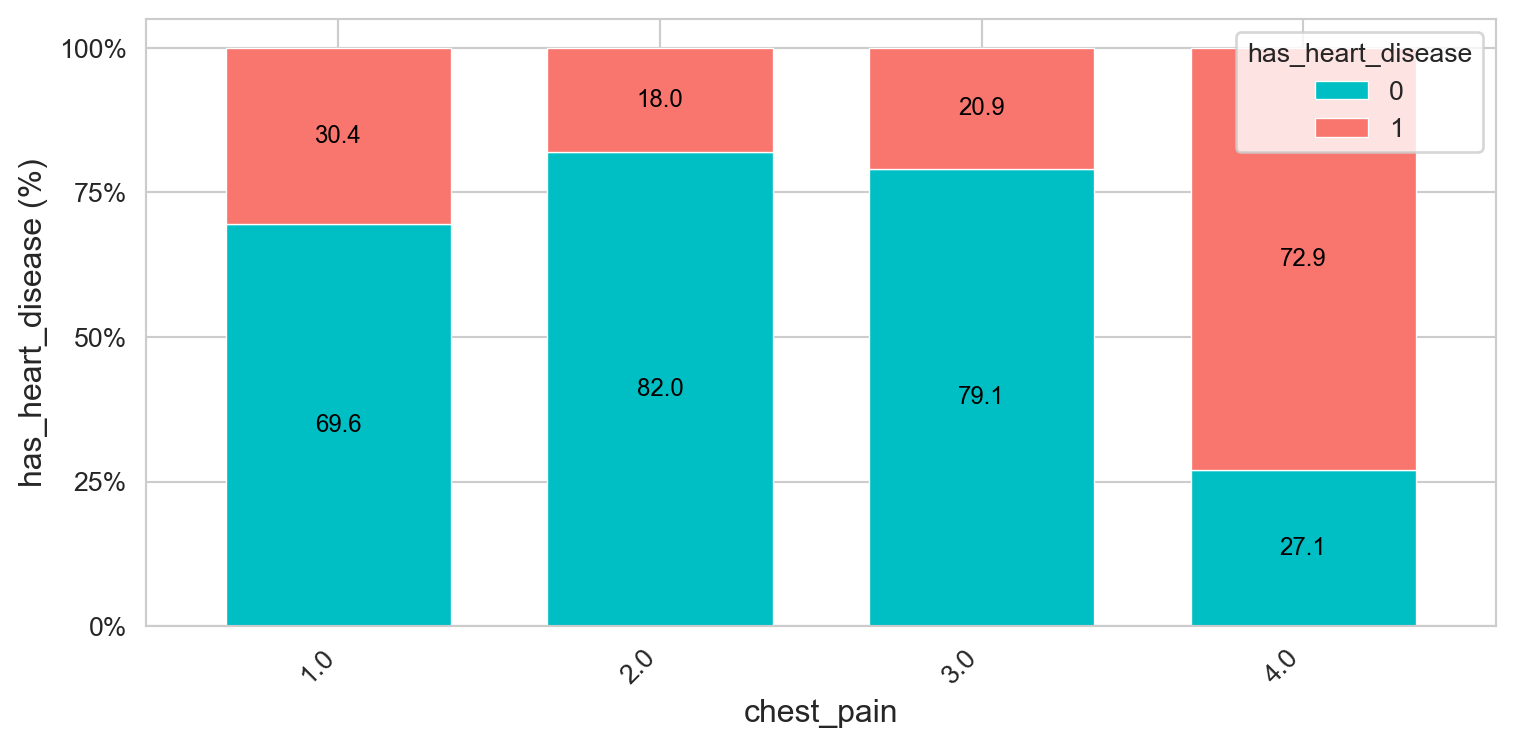
La probabilidad de tener una enfermedad cardíaca es del 72,9% si el paciente tiene chest_pain=4. Más de 2 veces más probable que si tiene chest_pain=1 (72.9 vs 30.4%).
Algunas reflexiones…
Los datos son los mismos, pero el enfoque para explorarlos es diferente. Lo mismo ocurre cuando estamos creando un modelo predictivo, los datos ingresados en el espacio N-dimensional pueden ser abordados mediante diferentes modelos, como: Máquinas de vectores soporte (support vector machine o SVM, en inglés), Bosques aleatorios (random forests), etc.
Como un fotógrafo que dispara desde diferentes ángulos o desde diferentes cámaras. El objeto es siempre el mismo, pero la perspectiva brinda información diferente.
La combinación de tablas en crudo y diferentes gráficos nos da una perspectiva de objeto más real y complementaria.
1.2.10 Análisis de correlación basado en la Teoría de la Información
Basándose en la medición del MIC, la función mine puede recibir el índice de la columna a predecir (o para obtener todas las correlaciones contra una sola variable).
target = 'has_heart_disease'
df_predictive = (mine_res_hd_mic[target].drop(target)
.sort_values(ascending=True)
.reset_index().rename(columns={'index': 'variable', target: 'mic'}))
fig, ax = plt.subplots(figsize=(6, 5))
ax.barh(df_predictive['variable'], df_predictive['mic'],
color=plt.cm.tab10(np.linspace(0, 1, len(df_predictive))))
ax.set(xlabel='Variable Importance (based on MIC)')
ax.grid(True, alpha=0.3, axis='x')
plt.tight_layout(); plt.show()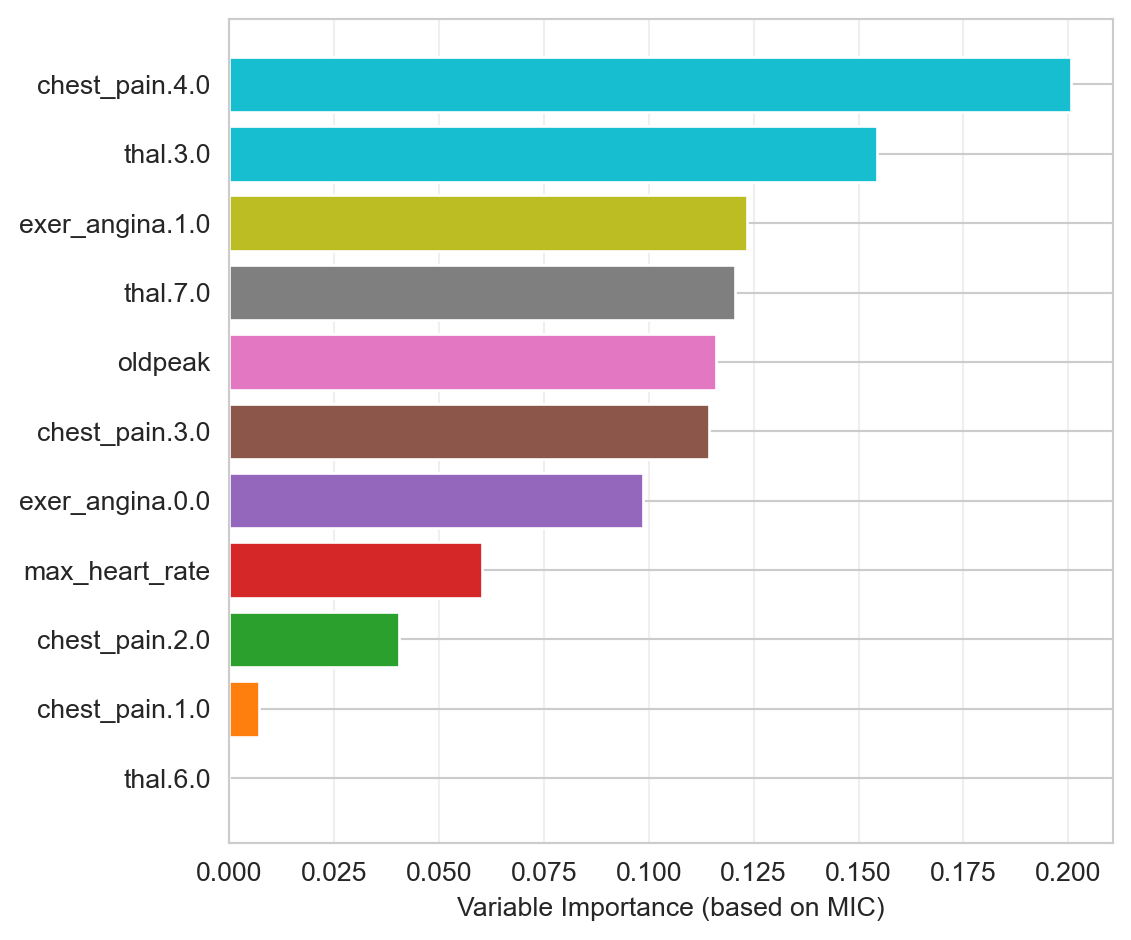
Aunque es recomendable ejecutar las correlaciones entre todas las variables para excluir factores ingresados correlacionados.
1.2.10.1 Consejos prácticos al utilizar mine
Si lleva demasiado tiempo, consideren tomar una muestra. Si hay muy pocos datos, consideren utilizar un valor más alto en el parámetro alpha, 0.6 es el valor por defecto. También se puede ejecutar en paralelo, configurando el parámetro n.cores=3 si tienen 4 cores (en R). En Python se puede paralelizar con joblib o multiprocessing. Una buena práctica en general cuando se ejecutan procesos paralelos, el core extra será utilizado por el sistema operativo.
1.2.11 ¿Sólo MINE cubre esto?
No. Sólo usamos la suite de MINE, pero hay otros algoritmos relacionados con información mutua. En Python algunos de los paquetes son: scikit-learn mutual_info y minepy.
El paquete funpymodeling introduce la función var_rank_info, que calcula varias métricas de la Teoría de la Información, como vimos en la sección Análisis de correlación basado en la Teoría de la Información.
En Python se puede calcular información mutua mediante scikit-learn, aquí un ejemplo.
El concepto trasciende la herramienta.
1.2.11.1 Otro ejemplo de correlación (información mutua)
Esta vez utilizaremos el concepto de información mutua (equivalente al paquete infotheo de R). Primero tenemos que hacer un paso de preparación de datos, aplicando una función discretize (o de binning). Convierte todas las variables numéricas a categóricas basándose en criterios de igual frecuencia.
El siguiente código creará la matriz de correlación como hemos visto antes, pero basándose en el índice de información mutua:
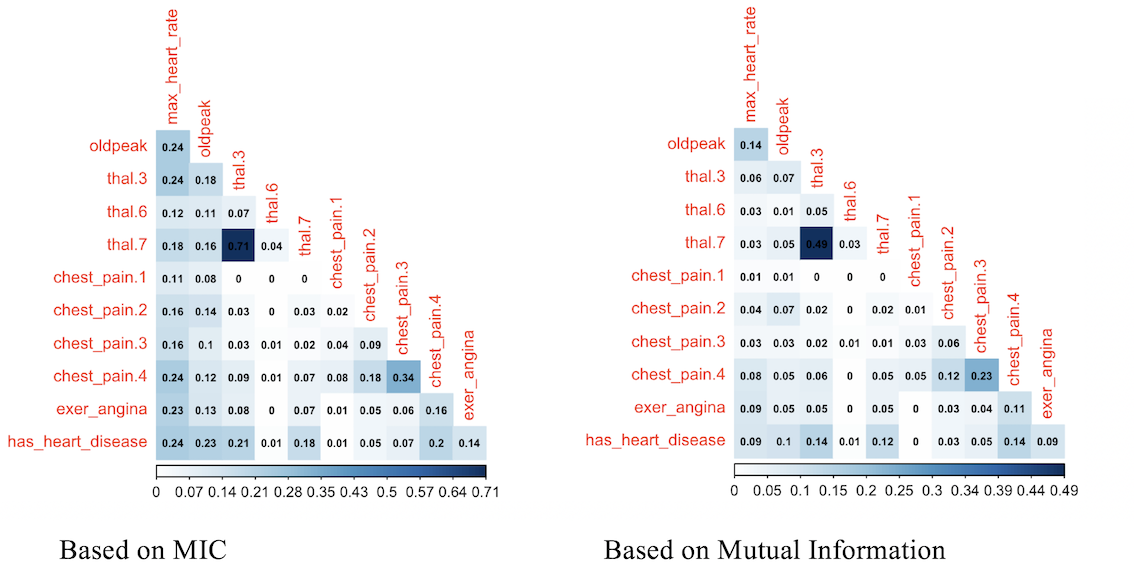
El puntaje de correlación basado en información mutua ordena las relaciones de una forma bastante similar al MIC, ¿no es cierto?
1.2.12 Medidas de información: Una perspectiva general
Más allá de la correlación, MIC y otras medidas de información identifican si hay una relación funcional.
Un alto MIC indica que la relación entre las dos variables puede explicarse por una función. Es nuestro trabajo encontrar esa función o modelo predictivo.
Este análisis se extiende a n-variables, este libro introduce otro algoritmo en el capítulo de Selección de las mejores variables.
Algunos modelos predictivos funcionan mejor que otros, pero si la relación es absolutamente ruidosa, sin importar cuán avanzado sea el algoritmo, los resultados serán malos.
Hay mucho más sobre la Teoría de la Información más adelante. Por ahora, pueden investigar estas lecturas didácticas:
- Video introductorio de 7 minutos
- Slides: Information Theory (Smola)
- Mutual information (Scholarpedia)
1.2.13 Conclusiones
El Cuarteto de Anscombe nos enseñó la buena práctica de combinar la estadística cruda con un gráfico.
Pudimos ver cómo el ruido puede afectar la relación entre dos variables, y este fenómeno siempre aparece en los datos. El ruido en los datos confunde al modelo predictivo.
El ruido está relacionado con el error, y puede ser estudiado con medidas basadas en la Teoría de la Información, tales como información mutua y MIC, que van un paso más allá de la típica R cuadrado. Existe un estudio clínico que utiliza MINE como selector de características en(Caban et al. 2012).
Estos métodos son aplicables en ingeniería de factores (feature engineering) como un método que no se basa en un modelo predictivo para clasificar las variables más importantes. También se aplica a las series temporales agrupadas.
Siguiente capítulo recomendado: Selección de las mejores variables
![]()
Caban, Juan J, Anand Joshi, y Paul Nagy. 2012. «Network-based classification and biomarker identification». Cancer informatics 11: CIN-S9386.
Lin, Jessica, Eamonn Keogh, Li Wei, y Stefano Lonardi. 2007. «Experiencing SAX: a novel symbolic representation of time series». Data Mining and knowledge discovery 15 (2): 107-44.
Monotonic function. s. f. Https://en.wikipedia.org/wiki/Monotonic_function.
Skewness and Kurtosis. s. f. Https://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm.
Understanding Skewness and Kurtosis. s. f. Https://codeburst.io/2-important-statistics-terms-you-need-to-know-in-data-science-skewness-and-kurtosis-388fef94eeaa.