5 APÉNDICE
Lectura complementaria.
5.1 La magia de los percentiles
El percentil es un concepto tan crucial en el análisis de datos que vamos a cubrirlo ampliamente en este libro. Considera cada observación con respecto a las demás. Un número aislado puede no ser significativo, pero cuando se compara con otros, aparece el concepto de distribución.
Los percentiles se utilizan en el análisis numérico, así como en la evaluación del rendimiento de un modelo predictivo.
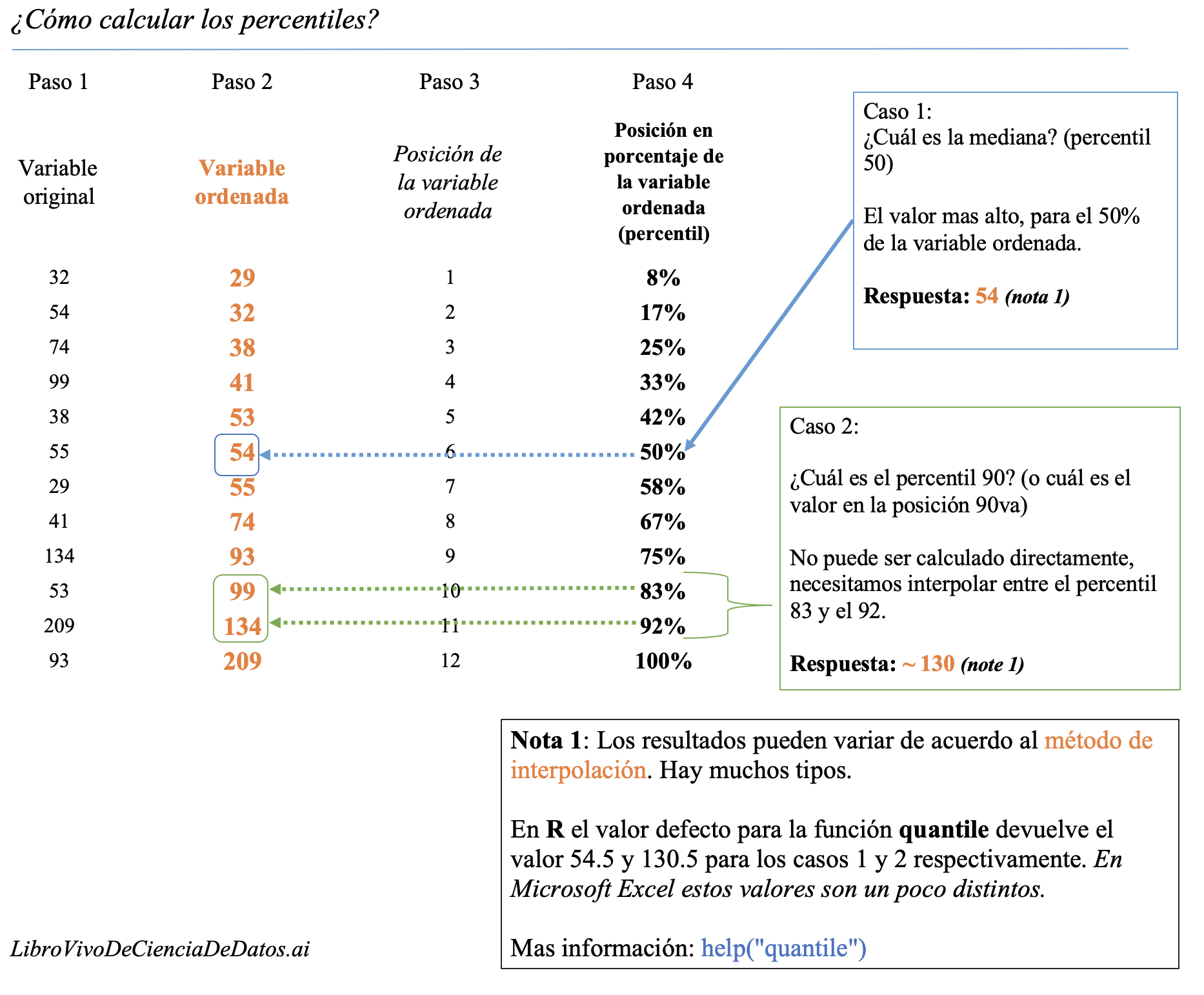
Figure 5.1: Cómo calcular percentiles
El conjunto de datos, un consejo antes de continuar:
Esto contiene muchos indicadores sobre el desarrollo mundial. Independientemente del ejemplo del análisis numérico, la idea es proporcionar una tabla lista para usar para sociólogos, investigadores, etc. interesados en analizar este tipo de datos.
La fuente de datos original es: http://databank.worldbank.org. Ahí encontrarán un diccionario de datos que explica todas las variables.
En esta sección utilizaremos una tabla que ya está preparada para el análisis. La preparación completa de los datos paso a paso se encuentra en el capítulo Análisis numérico.
Pueden buscar el significado de cualquier indicador en data.worldbank.org. Por ejemplo, si queremos saber qué significa EN.POP.SLUM.UR.ZS, entonces escribimos: http://data.worldbank.org/indicator/EN.POP.SLUM.UR.ZS
5.1.1 Cómo calcular percentiles
Existen varios métodos para obtener el percentil. Basado en interpolaciones, la forma más fácil es ordenar la variable de forma ascendente, seleccionando el percentil que deseamos (por ejemplo, 75%), y luego observando cuál es el valor máximo si queremos elegir el 75% de la población ordenada.
Ahora vamos a usar la técnica de mantener la muestra pequeña para que podamos tener el máximo control sobre lo que está sucediendo detrás del cálculo.
Conservamos los 10 países aleatorios y visualizamos el vector de rural_poverty_headcount, que es la variable que vamos a utilizar.
library(dplyr)
data_world_wide =
read.delim(file="https://goo.gl/NNYhCW",
header = T
)data_sample=filter(data_world_wide, Country.Name %in% c("Kazakhstan", "Zambia", "Mauritania", "Malaysia", "Sao Tome and Principe", "Colombia", "Haiti", "Fiji", "Sierra Leone", "Morocco")) %>% arrange(rural_poverty_headcount)
select(data_sample, Country.Name, rural_poverty_headcount)## Country.Name rural_poverty_headcount
## 1 Malaysia 1.6
## 2 Kazakhstan 4.4
## 3 Morocco 14.4
## 4 Colombia 40.3
## 5 Fiji 44.0
## 6 Mauritania 59.4
## 7 Sao Tome and Principe 59.4
## 8 Sierra Leone 66.1
## 9 Haiti 74.9
## 10 Zambia 77.9Tengan en cuenta que el vector se ordena sólo con fines didácticos. Como dijimos en el capítulo de Análisis numérico, a nuestros ojos les gusta el orden.
Ahora aplicamos la función “cuantitativa” a otra variable (el porcentaje de la población rural que vive por debajo de las líneas de pobreza):
quantile(data_sample$rural_poverty_headcount)## 0% 25% 50% 75% 100%
## 1.600 20.875 51.700 64.425 77.900Análisis
- Percentil 50%: el 50% de los países (cinco de ellos) tienen una
rural_poverty_headcountdebajo de51.7. Podemos comprobar esto en la última tabla: estos países son: Fiji, Colombia, Marruecos, Kazajistán, y Malasia. - Percentil 25%: el 25% de los países están por debajo de 20.87. Aquí podemos ver una interpolación porque el 25% representa ~2.5 países. Si utilizamos este valor para filtrar los países, entonces tendremos tres países: Marruecos, Kazajistán, y Malasia.
Más información sobre los diferentes tipos de cuantiles y sus interpolaciones: help("quantile").
5.1.1.1 Obtener las descripciones semánticas
Del último ejemplo podemos afirmar que:
- “La mitad de los países tienen hasta un 51.7% de pobreza rural”
- “Tres cuartas partes de los países tienen un máximo de 64.4% en cuanto a su pobreza rural” (basado en los países ordenados ascendentemente).
También podemos pensar en usar lo contrario:
- “Una cuarta parte de los países que presentan los valores más altos de pobreza rural tienen un porcentaje de por lo menos 64.4%”
5.1.2 Calcular cuantiles personalizados
Típicamente, queremos calcular ciertos cuantiles. La variable de ejemplo será el gini_index.
¿Qué es el Índice de Gini?
Es una medida de la desigualdad de ingresos o de riqueza.
- Un coeficiente de Gini de cero expresa igualdad perfecta donde todos los valores son iguales (por ejemplo, donde todos tienen los mismos ingresos).
- Un coeficiente de Gini de 1 (o 100%) expresa desigualdad máxima entre los valores (por ejemplo, en un gran número de personas, donde sólo una persona tiene todos los ingresos o el consumo mientras que todas las demás no tienen ninguno, el coeficiente de Gini será muy cercano a uno).
Fuente: https://en.wikipedia.org/wiki/Gini_coefficient
Ejemplo en R:
Si queremos obtener los cuantiles de 20, 40, 60, y 80 de la variable del índice de Gini, volvemos a usar la función quantile.
El parámetro na.rm=TRUE es necesario si tenemos valores vacíos como en este caso:
# También podemos obtener múltiples cuantiles en simultáneo
p_custom=quantile(data_world_wide$gini_index, probs = c(0.2, 0.4, 0.6, 0.8), na.rm=TRUE)
p_custom## 20% 40% 60% 80%
## 31.624 35.244 41.076 46.1485.1.3 Indicar dónde están la mayoría de los valores
En estadística descriptiva, queremos describir la población en términos generales. Podemos hablar de rangos usando dos percentiles. Tomemos los percentiles 10 y 90 para describir al 80% de la población.
La pobreza oscila entre el 0.075% y el 54.4% en el 80% de los países. (80% porque hicimos percentil 90 - percentil 10, centrándonos en la mitad de la población.)
Si consideramos al 80% como la mayoría de la población, entonces podríamos decir: “Normalmente (o en términos generales), la pobreza pasa de 0.07% a 54.4%”. Esta es una descripción semántica.
Observamos al 80% de la población, que parece ser un buen número para describir dónde están la mayoría de los casos. También podríamos haber usado el rango del 90% (percentil 95 - percentil 5).
5.1.3.1 ¿El percentil se relaciona con el cuartil?
Cuartil es el nombre formal para los percentiles 25, 50 y 75 (cuartos o ‘Q’). Si queremos observar el 50% de la población, debemos restar el 3er cuartil (o percentil 75) del 1er cuartil (percentil 25) para saber dónde está concentrado el 50% de los datos, también conocido como el rango intercuartil o IQR.
Percentil vs. cuantil vs. cuartil
0 cuartil = 0 cuantil = 0 percentil
1 cuartil = 0.25 cuantil = 25 percentil
2 cuartil = .5 cuantil = 50 percentil (mediana)
3 cuartil = .75 cuantil = 75 percentil
4 cuartil = 1 cuantil = 100 percentil5.1.4 Visualizar cuantiles
Graficar un histograma junto a los lugares donde se encuentra cada percentil puede ayudarnos a entender el concepto:
quantiles_var =
quantile(data_world_wide$poverty_headcount_1.9,
c(0.25, 0.5, 0.75),
na.rm = T
)
df_p = data.frame(value=quantiles_var,
quantile=c("25th", "50th", "75th")
)
library(ggplot2)
ggplot(data_world_wide, aes(poverty_headcount_1.9)) +
geom_histogram() +
geom_vline(data=df_p,
aes(xintercept=value,
colour = quantile),
show.legend = TRUE,
linetype="dashed"
) +
theme_light()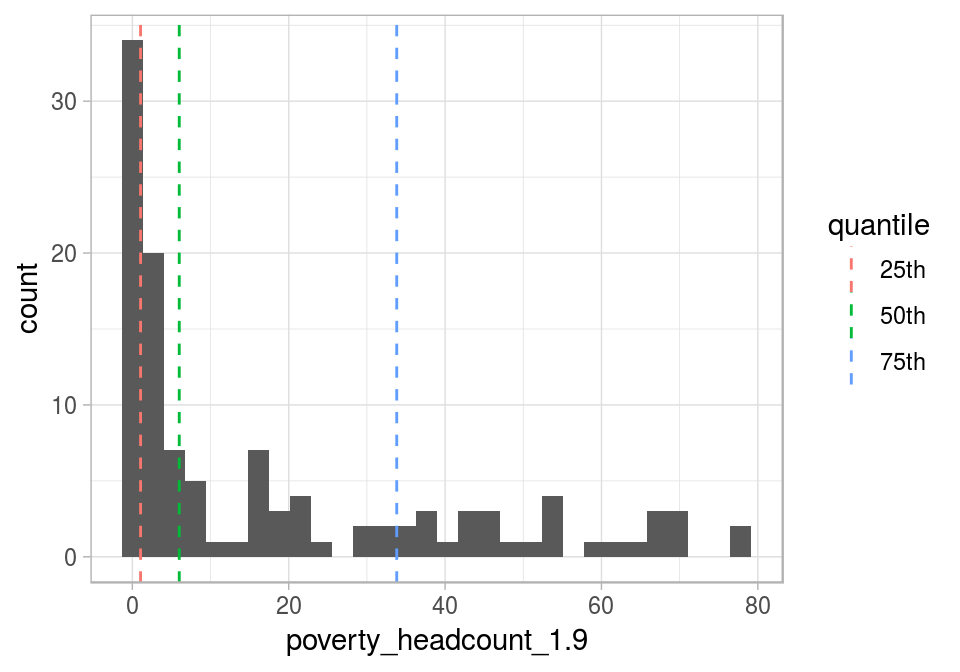
Figure 5.2: Visualizar cuantiles
Si sumamos todas las barras grises antes del percentil 25, tendrán aproximadamente la misma altura acumulada que la suma de las barras grises después del percentil 75.
En el último gráfico, el IQR aparece entre la primera y la última línea punteada y contiene el 50% de la población.
5.1.5 Conceptos de clasificación y top/bottom ‘X%’
El concepto de clasificación es el mismo que el de las competiciones. Nos permite responder ¿cuál es el país con la tasa más alta en la variable pop_living_slums?
Usaremos la función dense_rank del paquete ggplot2. Asigna la posición (puesto) a cada país, pero las necesitamos en orden inverso; es decir, asignamos el rank = 1 al valor más alto.
Ahora la variable será: La población que vive en hogares marginales es la proporción de la población urbana que vive en hogares marginales. Un hogar marginal se define como un grupo de individuos que viven bajo el mismo techo y que carecen de una o más de las siguientes condiciones: acceso a agua potable, acceso a saneamiento mejorado, suficiente área habitable y durabilidad de la vivienda.
La pregunta a responder: ¿Cuáles son los seis países con las tasas más altas de personas que viven en hogares marginales?
# Crear la variable de clasificación
data_world_wide$rank_pop_living_slums =
dense_rank(-data_world_wide$pop_living_slums) # Ordenar los datos según la clasificación
data_world_wide=arrange(data_world_wide, rank_pop_living_slums)
# Visualizar los primeros seis resultados
select(data_world_wide, Country.Name, rank_pop_living_slums) %>% head(.) ## Country.Name rank_pop_living_slums
## 1 South Sudan 1
## 2 Central African Republic 2
## 3 Sudan 3
## 4 Chad 4
## 5 Sao Tome and Principe 5
## 6 Guinea-Bissau 6También podemos preguntar: ¿En qué posición está Ecuador?
filter(data_world_wide, Country.Name=="Ecuador") %>% select(rank_pop_living_slums)## rank_pop_living_slums
## 1 575.1.5.0.1 Concepto de top/bottom ‘X%’
Otra pregunta que podría interesarnos responder: ¿Cuál es el valor con el que obtengo el 10% superior de los valores más bajos?
El percentil 10 es la respuesta:
quantile(data_world_wide$pop_living_slums, probs=.1, na.rm = T)## 10%
## 12.5Trabajando en lo opuesto: ¿Cuál es el valor con el que obtengo el 10% inferior de los valores más altos?
El percentil 90 es la respuesta, podemos filtrar todos los casos por encima de este valor:
quantile(data_world_wide$pop_living_slums,
probs=.9,
na.rm = T
) ## 90%
## 75.25.1.6 Uso de percentiles en el scoring de datos
Hay dos capítulos que usan este concepto:
La idea básica es desarrollar un modelo predictivo que prediga una variable binaria (yes/no). Supongamos que necesitamos puntuar nuevos casos, por ejemplo, para utilizarlos en una campaña de marketing. La pregunta a responder es:
¿Cuál es el valor del puntaje que deberíamos sugerirle a los ejecutivos de ventas para capturar el 50% de las nuevas ventas potenciales? La respuesta proviene de una combinación de análisis de percentil sobre el valor del puntaje más el análisis acumulativo de la variable objetivo actual.
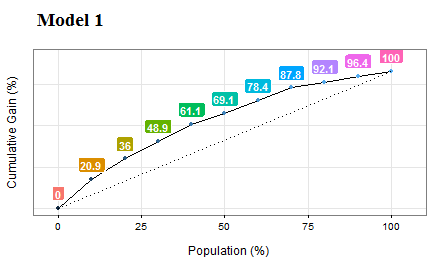
Figure 5.3: Curvas de ganancia y lift (desempeño del modelo)
5.1.6.1 Estudio de caso: Distribución de la riqueza
La distribución de la riqueza es similar a la del índice de Gini y se centra en la desigualdad. Mide los activos de los propietarios (que son diferentes de los ingresos), haciendo que la comparación entre países sea más uniforme con lo que las personas pueden adquirir según el lugar en el que viven. Para una mejor definición, consulten el artículo de Wikipedia y el Informe sobre el patrimonio mundial 2013. Referencias: (Wikipedia 2017a) y (Suisse 2013), respectivamente.
Citando a Wikipedia (Ref. (Wikipedia 2017a)):
la mitad de la riqueza mundial pertenece al 1% de la población;
el 10% superior de los adultos posee el 85%, mientras que el 90% inferior posee el 15% restante de la riqueza total del mundo; y
el 30% de los adultos más ricos poseen el 97% de la riqueza total.
Al igual que antes, a partir de la tercera frase podemos afirmarlo: “El 3% de la riqueza total se distribuye entre el 70% de los adultos”.
Las métricas top 10% y top 30% son los quantiles 0.1 y 0.3. La riqueza es la variable numérica.
![]()
5.2 Quick-start funModeling
Este paquete contiene un conjunto de funciones relacionadas con el análisis exploratorio de datos, la preparación de datos y el desempeño del modelo. Es utilizado por personas procedentes de los negocios, la investigación y la docencia (profesores y estudiantes).
El paquete funModeling está íntimamente relacionado con este libro, en el sentido de que la mayor parte de su funcionalidad se utiliza para explicar los diferentes temas abordados por el libro.
5.2.1 Abriendo la caja negra
Algunas funciones tienen comentarios incluidos en las líneas para que el usuario pueda abrir la caja negra y aprender cómo se desarrolló, o para afinar o mejorar cualquiera de ellas.
Todas las funciones están bien documentadas, explicando todos los parámetros con la ayuda de muchos ejemplos breves. Se puede acceder a la documentación en R a través de: help("name_of_the_function").
Cambios importantes desde la última versión 1.6.7, (esto sólo es relevante si estaban usando versiones anteriores):
A partir de la última versión, 1.6.7 (21 de enero de 2018), los parámetros str_input, str_target y str_score se renombrarán a input, target y score respectivamente. La funcionalidad sigue siendo la misma. Si estaban utilizando estos nombres de parámetros en producción, seguirán funcionando hasta la próxima versión. Esto significa que, por ahora, pueden utilizar, por ejemplo, str_input o input.
El otro cambio importante fue en discretize_get_bins, que se detalla más adelante en este documento.
5.2.1.1 Sobre este quick-start
Este quick-start se centra sólo en las funciones. Pueden consultar todas las explicaciones en torno a ellas, así como el cómo y cuándo utilizarlas, siguiendo los enlaces “Leer más aquí.” que se encuentran debajo de cada sección, que los redirigirán al libro.
A continuación está la mayoría de las funciones de funModeling divididas por categoría.
5.2.2 Análisis exploratorio de datos
5.2.2.1 df_status: Estado de salud de un conjunto de datos
Caso de uso: analiza los ceros, los valores faltantes (NA), el infinito, el tipo de datos y el número de valores únicos para un conjunto de datos determinado.
library(funModeling)
df_status(heart_disease)## variable q_zeros p_zeros q_na p_na q_inf p_inf type
## 1 age 0 0.00 0 0.00 0 0 integer
## 2 gender 0 0.00 0 0.00 0 0 factor
## 3 chest_pain 0 0.00 0 0.00 0 0 factor
## 4 resting_blood_pressure 0 0.00 0 0.00 0 0 integer
## 5 serum_cholestoral 0 0.00 0 0.00 0 0 integer
## 6 fasting_blood_sugar 258 85.15 0 0.00 0 0 factor
## 7 resting_electro 151 49.83 0 0.00 0 0 factor
## 8 max_heart_rate 0 0.00 0 0.00 0 0 integer
## 9 exer_angina 204 67.33 0 0.00 0 0 integer
## 10 oldpeak 99 32.67 0 0.00 0 0 numeric
## 11 slope 0 0.00 0 0.00 0 0 integer
## 12 num_vessels_flour 176 58.09 4 1.32 0 0 integer
## 13 thal 0 0.00 2 0.66 0 0 factor
## 14 heart_disease_severity 164 54.13 0 0.00 0 0 integer
## 15 exter_angina 204 67.33 0 0.00 0 0 factor
## 16 has_heart_disease 0 0.00 0 0.00 0 0 factor
## unique
## 1 41
## 2 2
## 3 4
## 4 50
## 5 152
## 6 2
## 7 3
## 8 91
## 9 2
## 10 40
## 11 3
## 12 4
## 13 3
## 14 5
## 15 2
## 16 2[🔎 Leer más aquí.]
5.2.2.2 plot_num: Graficar las distribuciones de variables numéricas
Solamente grafica variables numéricas.
plot_num(heart_disease)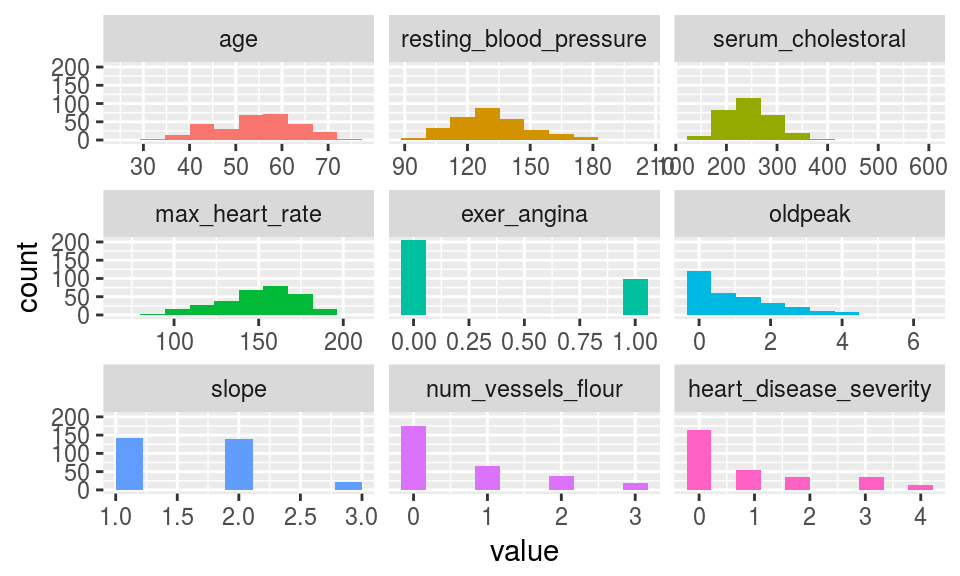
Figure 5.4: plot num: visualizar variables numéricas
Notas:
bins: configura la cantidad de segmentos (10 por defecto).path_out: indica el directorio donde se guardará el archivo; si tiene un valor, entonces el gráfico se exportará en formato jpeg. Para guardarlo en el directorio actual debe ser un punto: “.”
[🔎 Leer más aquí.]
5.2.2.3 profiling_num: Calcular varias estadísticas para variables numéricas
Obtiene varias estadísticas para variables numéricas.
profiling_num(heart_disease)## variable mean std_dev variation_coef p_01 p_05 p_25
## 1 age 54.44 9.04 0.17 35 40 48
## 2 resting_blood_pressure 131.69 17.60 0.13 100 108 120
## 3 serum_cholestoral 246.69 51.78 0.21 149 175 211
## 4 max_heart_rate 149.61 22.88 0.15 95 108 134
## 5 exer_angina 0.33 0.47 1.44 0 0 0
## 6 oldpeak 1.04 1.16 1.12 0 0 0
## 7 slope 1.60 0.62 0.38 1 1 1
## 8 num_vessels_flour 0.67 0.94 1.39 0 0 0
## 9 heart_disease_severity 0.94 1.23 1.31 0 0 0
## p_50 p_75 p_95 p_99 skewness kurtosis iqr range_98
## 1 56.0 61.0 68.0 71.0 -0.21 2.5 13.0 [35, 71]
## 2 130.0 140.0 160.0 180.0 0.70 3.8 20.0 [100, 180]
## 3 241.0 275.0 326.9 406.7 1.13 7.4 64.0 [149, 406.74]
## 4 153.0 166.0 181.9 192.0 -0.53 2.9 32.5 [95.02, 191.96]
## 5 0.0 1.0 1.0 1.0 0.74 1.5 1.0 [0, 1]
## 6 0.8 1.6 3.4 4.2 1.26 4.5 1.6 [0, 4.2]
## 7 2.0 2.0 3.0 3.0 0.51 2.4 1.0 [1, 3]
## 8 0.0 1.0 3.0 3.0 1.18 3.2 1.0 [0, 3]
## 9 0.0 2.0 3.0 4.0 1.05 2.8 2.0 [0, 4]
## range_80
## 1 [42, 66]
## 2 [110, 152]
## 3 [188.8, 308.8]
## 4 [116, 176.6]
## 5 [0, 1]
## 6 [0, 2.8]
## 7 [1, 2]
## 8 [0, 2]
## 9 [0, 3]Nota:
plot_numyprofiling_numautomáticamente excluyen variables no numéricas
[🔎 Leer más aquí.]
5.2.2.4 freq: Obtener las distribuciones de frecuencia de variables categóricas
library(dplyr)
# Seleccionar sólo dos variables para este ejemplo
heart_disease_2=heart_disease %>% select(chest_pain, thal)
# Distribución de la frecuencia
freq(heart_disease_2)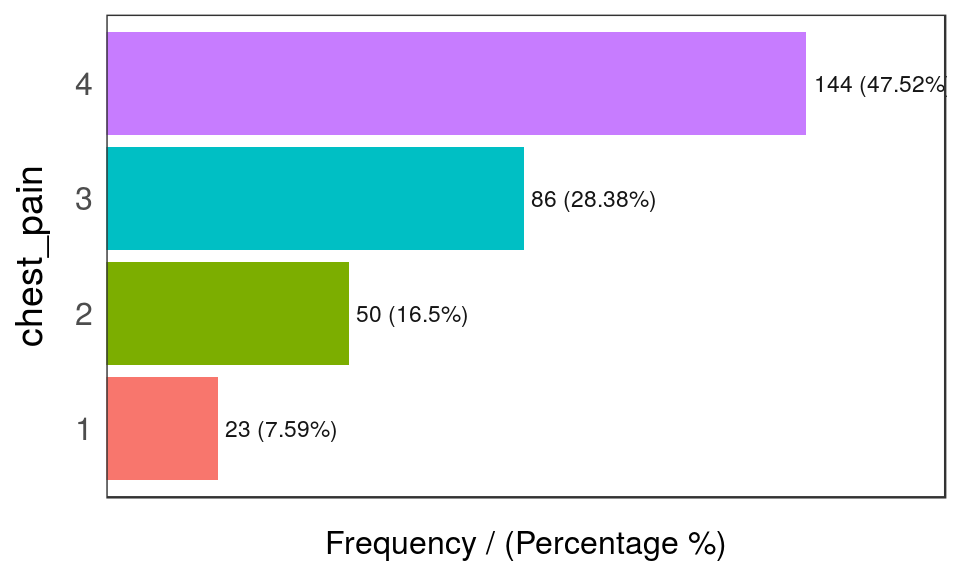
Figure 5.5: freq: visualizar variables categóricas
## chest_pain frequency percentage cumulative_perc
## 1 4 144 47.5 48
## 2 3 86 28.4 76
## 3 2 50 16.5 92
## 4 1 23 7.6 100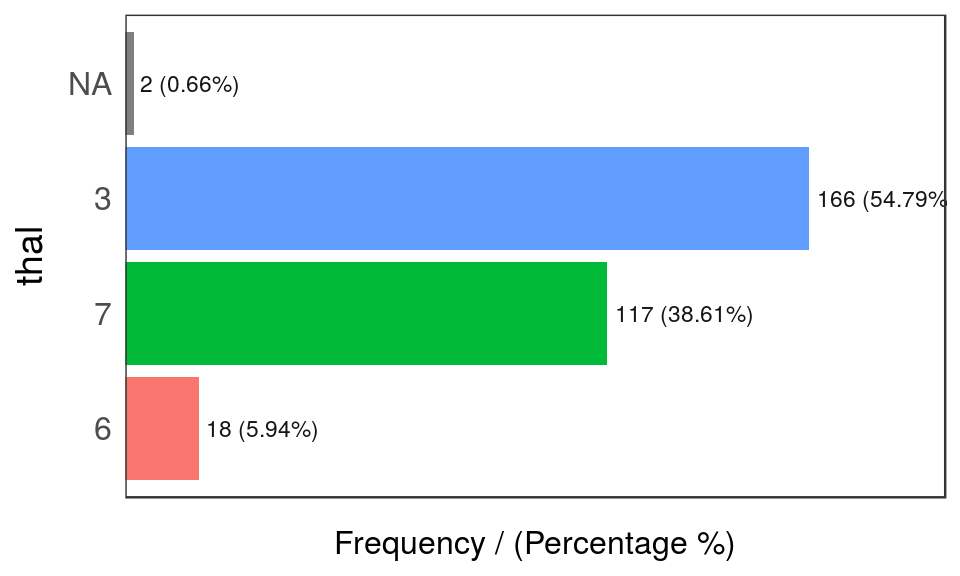
Figure 5.5: freq: visualizar variables categóricas
## thal frequency percentage cumulative_perc
## 1 3 166 54.79 55
## 2 7 117 38.61 93
## 3 6 18 5.94 99
## 4 <NA> 2 0.66 100## [1] "Variables processed: chest_pain, thal"Notas:
freqsólo procesa variablesfactorycharacter, excluyendo variables no categóricas.- Devuelve la tabla de distribución como un data frame.
- Si
inputestá vacío, entonces se ejecuta para todas las variables categóricas. path_outindica el directorio donde se guardará el archivo; si tiene un valor, entonces el gráfico se exportará en formato jpeg. Para guardarlo en el directorio actual debe ser un punto: “.”na.rmindica si los valoresNAdeberían ser excluidos (FALSEpor defecto).
[🔎 Leer más aquí.]
5.2.3 Correlaciones
5.2.3.1 correlation_table: Calcula el estadístico R
Obtiene la métrica R (o coeficiente de Pearson) para todas las variables numéricas, saltándose las categóricas.
correlation_table(heart_disease, "has_heart_disease")## Variable has_heart_disease
## 1 has_heart_disease 1.00
## 2 heart_disease_severity 0.83
## 3 num_vessels_flour 0.46
## 4 oldpeak 0.42
## 5 slope 0.34
## 6 age 0.23
## 7 resting_blood_pressure 0.15
## 8 serum_cholestoral 0.08
## 9 max_heart_rate -0.42Notas:
- Sólo se analizan las variables numéricas. La variable objetivo debe ser numérica.
- Si la variable objetivo es categórica, entonces será convertida a numérica.
[🔎 Leer más aquí.]
5.2.3.2 var_rank_info: Correlación basada en Teoría de la Información
Calcula la correlación basándose en distintas métricas de la Teoría de la Información entre todas las variables de un data frame y una variable objetivo.
var_rank_info(heart_disease, "has_heart_disease")## var en mi ig gr
## 1 heart_disease_severity 1.8 0.995 0.99508 0.53907
## 2 thal 2.0 0.209 0.20946 0.16805
## 3 exer_angina 1.8 0.139 0.13914 0.15264
## 4 exter_angina 1.8 0.139 0.13914 0.15264
## 5 chest_pain 2.5 0.205 0.20502 0.11803
## 6 num_vessels_flour 2.4 0.182 0.18152 0.11577
## 7 slope 2.2 0.112 0.11242 0.08688
## 8 serum_cholestoral 7.5 0.561 0.56056 0.07956
## 9 gender 1.8 0.057 0.05725 0.06330
## 10 oldpeak 4.9 0.249 0.24917 0.06036
## 11 max_heart_rate 6.8 0.334 0.33362 0.05407
## 12 resting_blood_pressure 5.6 0.143 0.14255 0.03024
## 13 age 5.9 0.137 0.13718 0.02705
## 14 resting_electro 2.1 0.024 0.02415 0.02219
## 15 fasting_blood_sugar 1.6 0.000 0.00046 0.00076Nota: Analiza variables numéricas y categóricas. También se utiliza con el método de discretización numérica como antes, tal como discretize_df.
[🔎 Leer más aquí.]
5.2.3.3 cross_plot: Gráfico de distribución entre variable de entrada y variable objetivo
Obtiene la distribución relativa y absoluta entre una variable de entrada y una variable objetivo. Es útil para explicar y reportar si una variable es importante o no.
cross_plot(data=heart_disease, input=c("age", "oldpeak"), target="has_heart_disease")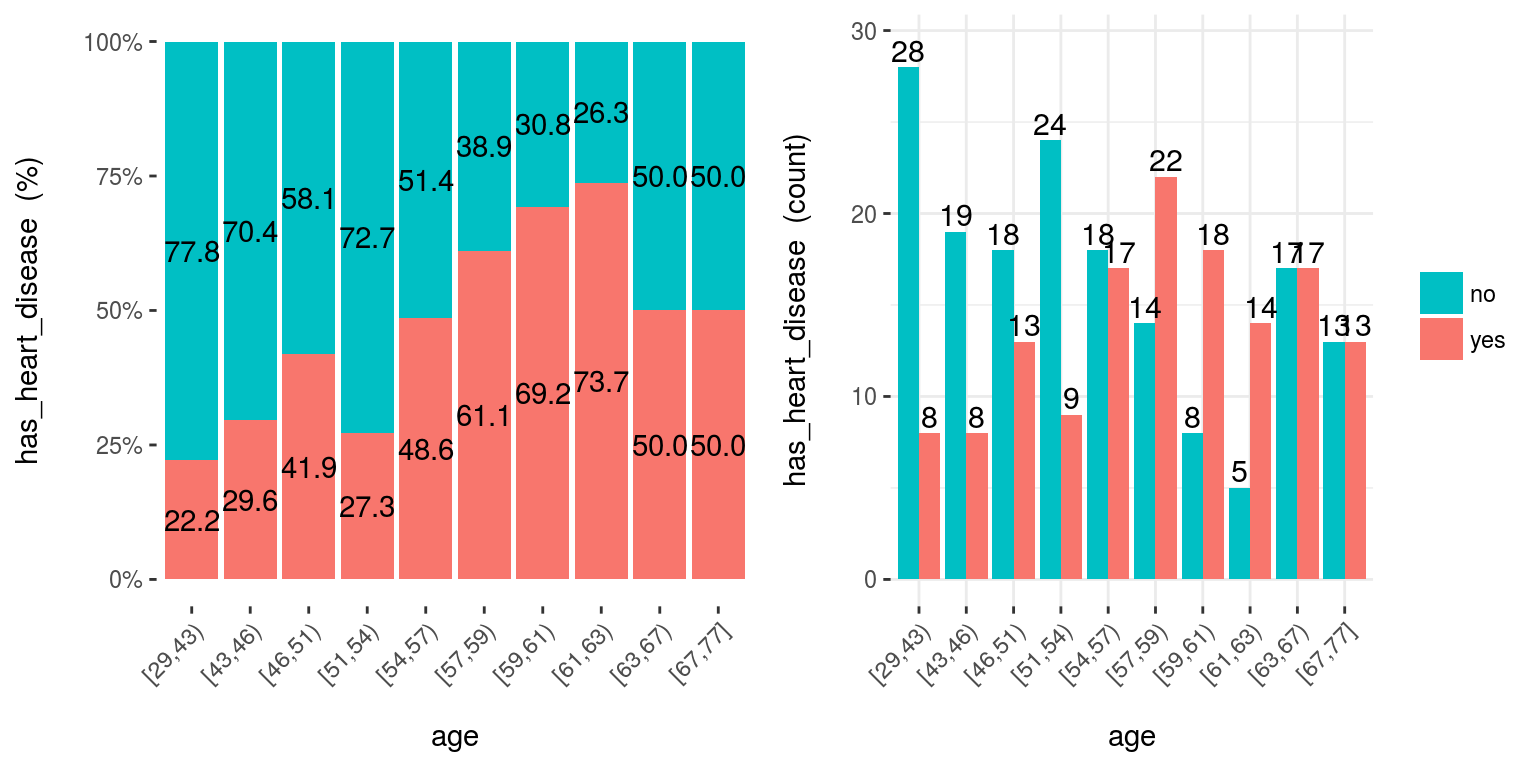
Figure 5.6: cross plot: Visualizar variable de entrada vs. variable objetivo
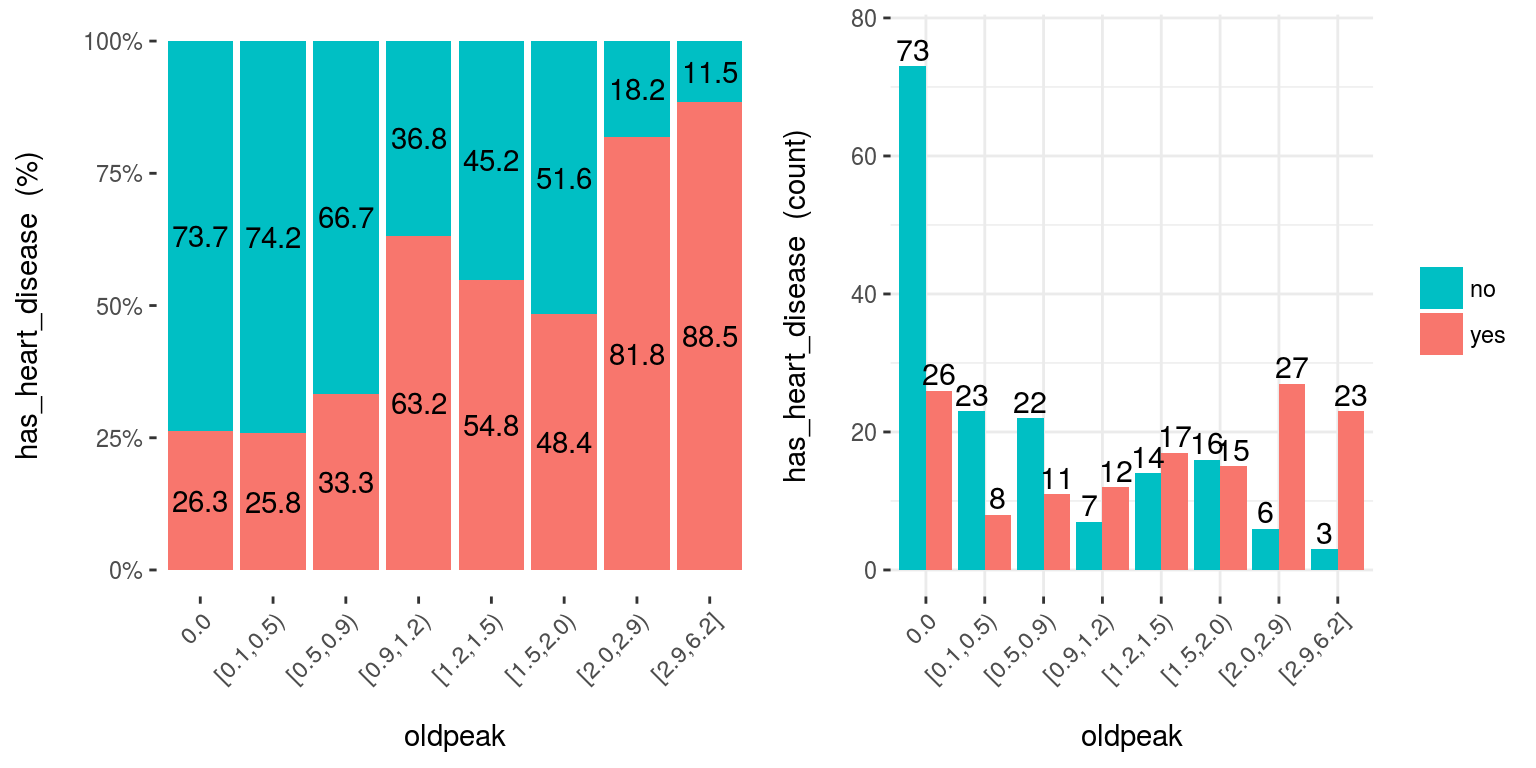
Figure 5.6: cross plot: Visualizar variable de entrada vs. variable objetivo
Notas:
auto_binning:TRUEpor defecto, muestra la variable numérica como categórica.path_outindica el directorio donde se guardará el archivo; si tiene un valor, entonces el gráfico se exportará en formato jpeg.inputpuede ser numérica o categórica, ytargetdebe ser una variable binaria (dos clases).- Si
inputestá vacío, entonces se ejecutará para todas las variables.
[🔎 Leer más aquí.]
5.2.3.4 plotar: Diagramas de caja e histogramas de densidad entre variables de entrada y objetivo
Es útil para explicar y reportar si una variable es importante o no.
Diagrama de caja:
plotar(data=heart_disease, input = c("age", "oldpeak"), target="has_heart_disease", plot_type="boxplot")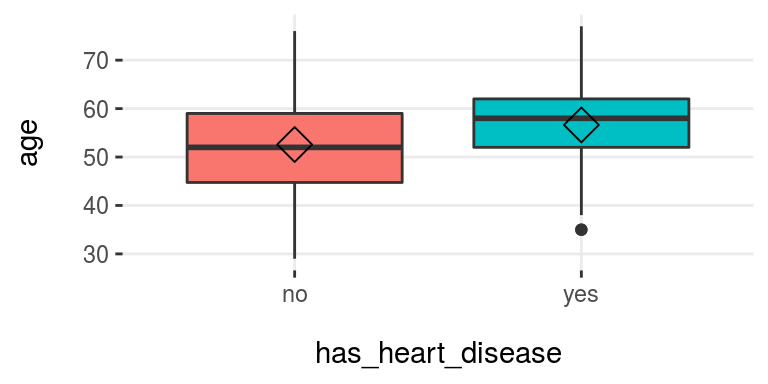
Figure 3.16: plotar (1): visualizar un diagrama de caja
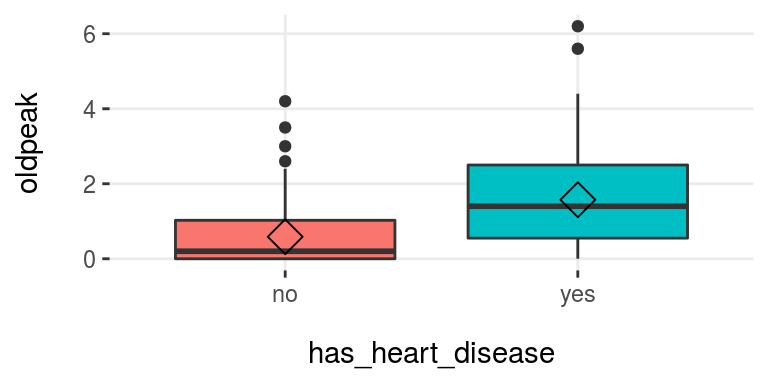
Figure 3.16: plotar (1): visualizar un diagrama de caja
[🔎 Leer más aquí.]
Histogramas de densidad:
plotar(data=mtcars, input = "gear", target="cyl", plot_type="histdens")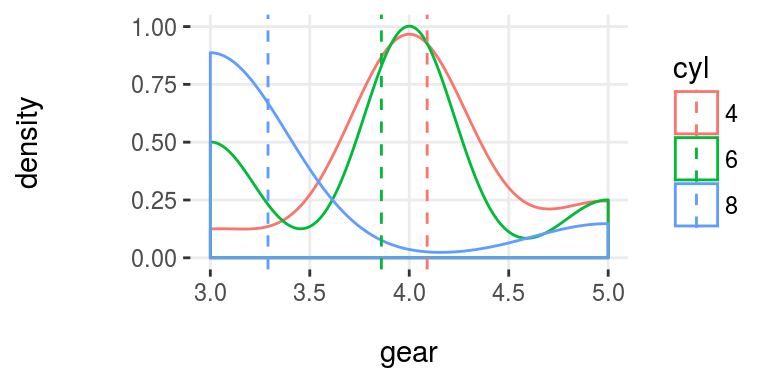
Figure 5.7: plotar (2): visualizar histograma de densidad
[🔎 Leer más aquí.]
Notes:
path_outindica el directorio donde se guardará el archivo; si tiene un valor, entonces el gráfico se exportará en formato jpeg.- Si
inputestá vacío, entonces se ejecuta para todas la variables numéricas (saltéandose las categóricas). inputdebe ser numérico y la variable objetivo debe ser categórica.targetpuede ser multi-clase (no sólo binario).
5.2.3.5 categ_analysis: Análisis cuantitativo para un resultado binario
Hace un análisis numérico de una variable binaria objetivo basándose en una variable categórica de entrada, la representatividad (perc_rows) y la precisión (perc_target) de cada valor de la variable de entrada; por ejemplo, la tasa de infección por gripe por país.
df_ca=categ_analysis(data = data_country, input = "country", target = "has_flu")
head(df_ca)## country mean_target sum_target perc_target q_rows perc_rows
## 1 Malaysia 1.00 1 0.012 1 0.001
## 2 Mexico 0.67 2 0.024 3 0.003
## 3 Portugal 0.20 1 0.012 5 0.005
## 4 United Kingdom 0.18 8 0.096 45 0.049
## 5 Uruguay 0.17 11 0.133 63 0.069
## 6 Israel 0.17 1 0.012 6 0.007Nota:
- La variable
inputdebe ser categórica. - La variable
targetdebe ser binaria (dos valores posibles).
Esta función se utiliza para analizar datos cuando necesitamos reducir la cardinalidad de las variables en el modelado predictivo.
[🔎 Leer más aquí.]
5.2.4 Preparación de datos
5.2.4.1 Discretización de datos
5.2.4.1.1 discretize_get_bins + discretize_df: Convertir variables numéricas a categóricas
Necesitamos dos funciones: discretize_get_bins, que devuelve los umbrales para cada variable, y luego discretize_df, que toma el resultado de la primera función y convierte las variables deseadas. El criterio de segmentación es el de igual frecuencia.
Ejemplo: convertir sólo dos variables de un conjunto de datos.
# Paso 1: Obtener los umbrales de las variables deseadas: "max_heart_rate" y "oldpeak"
d_bins=discretize_get_bins(data=heart_disease, input=c("max_heart_rate", "oldpeak"), n_bins=5)## [1] "Variables processed: max_heart_rate, oldpeak"# Paso 2: Aplicar el umbral para llegar al
# data frame final
heart_disease_discretized =
discretize_df(data=heart_disease,
data_bins=d_bins,
stringsAsFactors=T
)## [1] "Variables processed: max_heart_rate, oldpeak"La siguiente imagen ilustra el resultado. Por favor noten que el nombre de la variable no cambió.
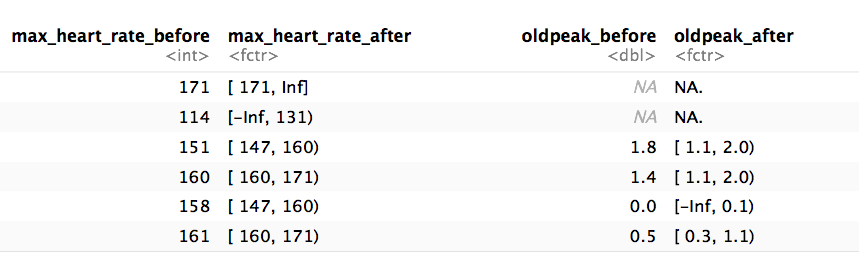
Figure 5.8: Resultados del proceso de discretización automática
Notas:
- Este procedimiento de dos pasos está pensado para ser utilizado en producción con nuevos datos.
- Los valores mín y máx de cada segmento serán
-InfeInf, respectivamente. - Un cambio en la última versión de
funModeling(1.6.7) puede alterar el resultado en algunos escenarios. Por favor verifiquen los resultados si están usando la versión 1.6.6. Más información sobre este cambio aquí.
{kind=link}
[🔎 Leer más aquí.]
5.2.4.2 convert_df_to_categoric: Convertir cada columna de un data frame a variables carácter
La segmentación, o el criterio de discretización para cualquier variable numérica es igual frecuencia. Las variables factor son convertidas directamente a variables carácter.
iris_char=convert_df_to_categoric(data = iris, n_bins = 5)
# Verificar las primeras filas
head(iris_char)5.2.4.3 equal_freq: Convertir variable numérica a categórica
Convierte un vector numérico en factor usando el criterio de igual frecuencia.
new_age=equal_freq(heart_disease$age, n_bins = 5)
# Verificar los resultados
Hmisc::describe(new_age)## new_age
## n missing distinct
## 303 0 5
##
## Value [29,46) [46,54) [54,59) [59,63) [63,77]
## Frequency 63 64 71 45 60
## Proportion 0.21 0.21 0.23 0.15 0.20[🔎 Leer más aquí.]
Notas:
- A diferencia de
discretize_get_bins, esta función no inserta-InfyInfcomo los valores mín y máx, respectivamente.
5.2.4.4 range01: Escala la variable en el rango de 0 a 1
Convierte un vector numérico a una escala que va de 0 a 1, donde 0 es el mínimo y 1 es el máximo.
age_scaled=range01(heart_disease$oldpeak)
# Verificar los resultados
summary(age_scaled)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 0.00 0.13 0.17 0.26 1.005.2.5 Preparación de datos con valores atípicos
5.2.5.1 hampel_outlier y tukey_outlier: Obtiene el umbral de los valores atípicos
Ambas funciones obtienen un vector de dos valores que indica el umbral en el que los valores son considerados atípicos. Las funciones tukey_outlier y hampel_outlier son utilizadas internamente en prep_outliers.
Usando el método de Tukey:
tukey_outlier(heart_disease$resting_blood_pressure)## bottom_threshold top_threshold
## 60 200[🔎 Leer más aquí.]
Usando el método de Hampel:
hampel_outlier(heart_disease$resting_blood_pressure)## bottom_threshold top_threshold
## 86 174[🔎 Leer más aquí.]
5.2.5.2 prep_outliers: Preparar los valores atípicos de un data frame
Toma un data frame y devuelve el mismo data frame más las transformaciones especificadas en el parámetro input. También funciona con un sólo vector.
Ejemplo tomando dos variables como datos de entrada:
# Obtener el umbral según el método de Hampel
hampel_outlier(heart_disease$max_heart_rate)## bottom_threshold top_threshold
## 86 220# Aplicar la función para frenar los valores atípicos en los valores del umbral
data_prep=prep_outliers(data = heart_disease, input = c('max_heart_rate','resting_blood_pressure'), method = "hampel", type='stop')Verificar el antes y después de la variable max_heart_rate:
## [1] "Before transformation -> Min: 71; Max: 202"## [1] "After transformation -> Min: 86.283; Max: 202"El valor mínimo cambió de 71 a 86.23, mientras que el valor máximo queda igual, en 202.
Notas:
methodpuede ser:bottom_top,tukeyohampel.typepuede ser:stoposet_na. Si esstoptodos los valores marcados como atípicos serán frenados en el umbral. Si esset_na, entonces los valores marcados serán tomados comoNA.
[🔎 Leer más aquí.]
5.2.6 Desempeño de un modelo predictivo
5.2.6.1 gain_lift: Curva de desempeño de ganancia y lift
Después de calcular los scores o probabilidades de la clase que queremos predecir, los pasamos a la función gain_lift, que devuelve un data frame con métricas de desempeño.
# Crear un modelo de machine learning y obtener sus puntajes para casos positivos
fit_glm=glm(has_heart_disease ~ age + oldpeak, data=heart_disease, family = binomial)
heart_disease$score=predict(fit_glm, newdata=heart_disease, type='response')
# Calcular las métricas de desempeño
gain_lift(data=heart_disease, score='score', target='has_heart_disease')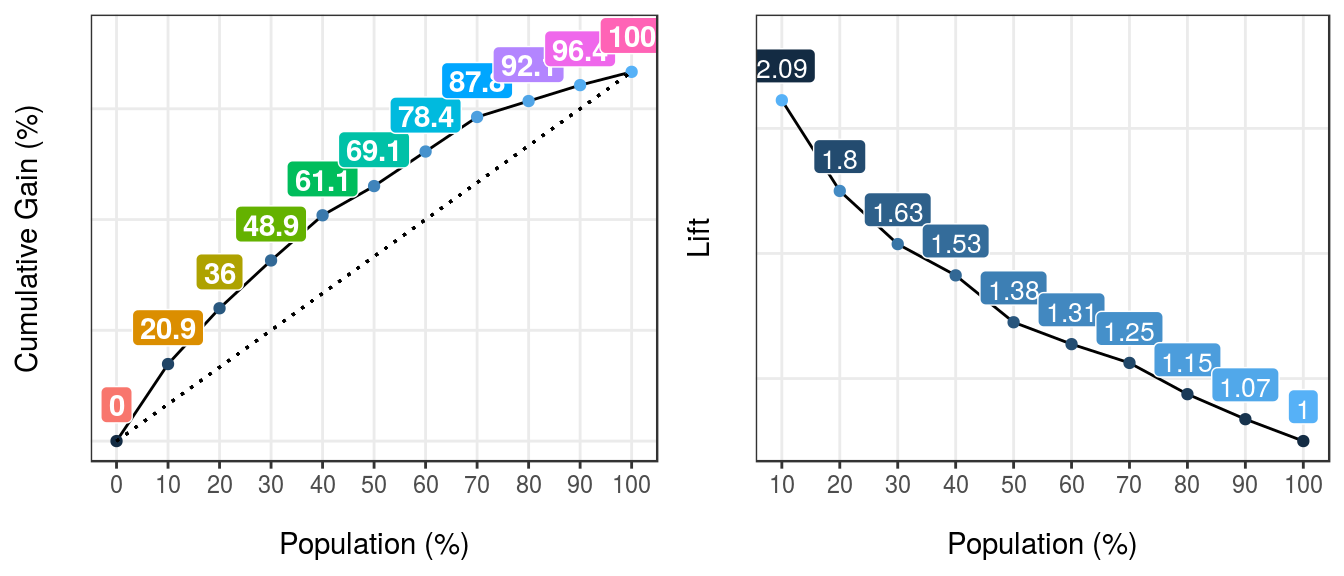
Figure 5.9: ganancia y lift: visualizando el desempeño de un modelo predictivo
## Population Gain Lift Score.Point
## 1 10 21 2.1 0.82
## 2 20 36 1.8 0.70
## 3 30 49 1.6 0.57
## 4 40 61 1.5 0.49
## 5 50 69 1.4 0.40
## 6 60 78 1.3 0.33
## 7 70 88 1.2 0.29
## 8 80 92 1.1 0.25
## 9 90 96 1.1 0.20
## 10 100 100 1.0 0.12[🔎 Leer más aquí.]
![]()
Referencias
stats.stackexchange.com. 2015. “Gradient Boosting Machine Vs Random Forest.” https://stats.stackexchange.com/questions/173390/gradient-boosting-tree-vs-random-forest.
2017a. “How to Interpret Mean Decrease in Accuracy and Mean Decrease Gini in Random Forest Models.” http://stats.stackexchange.com/questions/197827/how-to-interpret-mean-decrease-in-accuracy-and-mean-decrease-gini-in-random-fore. 2017b. “Percentile Vs Quantile Vs Quartile.” https://stats.stackexchange.com/questions/156778/percentile-vs-quantile-vs-quartile.Wikipedia. 2017a. “Distribution of Wealth.” https://en.wikipedia.org/wiki/Distribution_of_wealth.
Suisse, Credit. 2013. “Global Wealth Report 2013.” https://publications.credit-suisse.com/tasks/render/file/?fileID=BCDB1364-A105-0560-1332EC9100FF5C83.